Полносвязная сеть вычисляет последовательность аффинных преобразований и нелинейностей: . Для классификации используется softmax и кросс-энтропия . Обучение — минимизация функции потерь методом градиентного спуска (backpropagation).
Используемые библиотеки¶
Используем numpy, pandas, seaborn, matplotlib. Из sklearn — load_breast_cancer, train_test_split, StandardScaler, Pipeline, MLPClassifier, метрики классификации.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
sns.set_theme(style="whitegrid", palette="deep")
plt.rcParams["figure.dpi"] = 120
PRIMARY_COLOR = "#1f77b4"
HEATMAP_CMAP = "coolwarm"
CONFUSION_CMAP = "Blues"
Датасет: описание и частичная распечатка¶
Датасет Breast Cancer Wisconsin — 569 пациентов, 30 числовых признаков. Задача — бинарная классификация опухолей (злокачественная / доброкачественная). Нейросеть использует сложные нелинейные взаимодействия между признаками, которые линейные модели пропускают. Сравнительно небольшой датасет полезен для демонстрации MLPClassifier без переобучения.
breast = load_breast_cancer(as_frame=True)
data = breast.frame
print(f"Размерность: {data.shape}")
data.head()
Размерность: (569, 31)
Предварительная обработка¶
Разделяем признаки и метки, стратифицированный train/test split (80/20). StandardScaler критически важен для нейросетей: метод градиентного спуска сходится значительно медленнее при разных масштабах признаков — градиенты по одним весам будут огромными, по другим — ничтожными.
features = data.drop(columns=["target"])
target = data["target"]
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.2, random_state=42, stratify=target
)
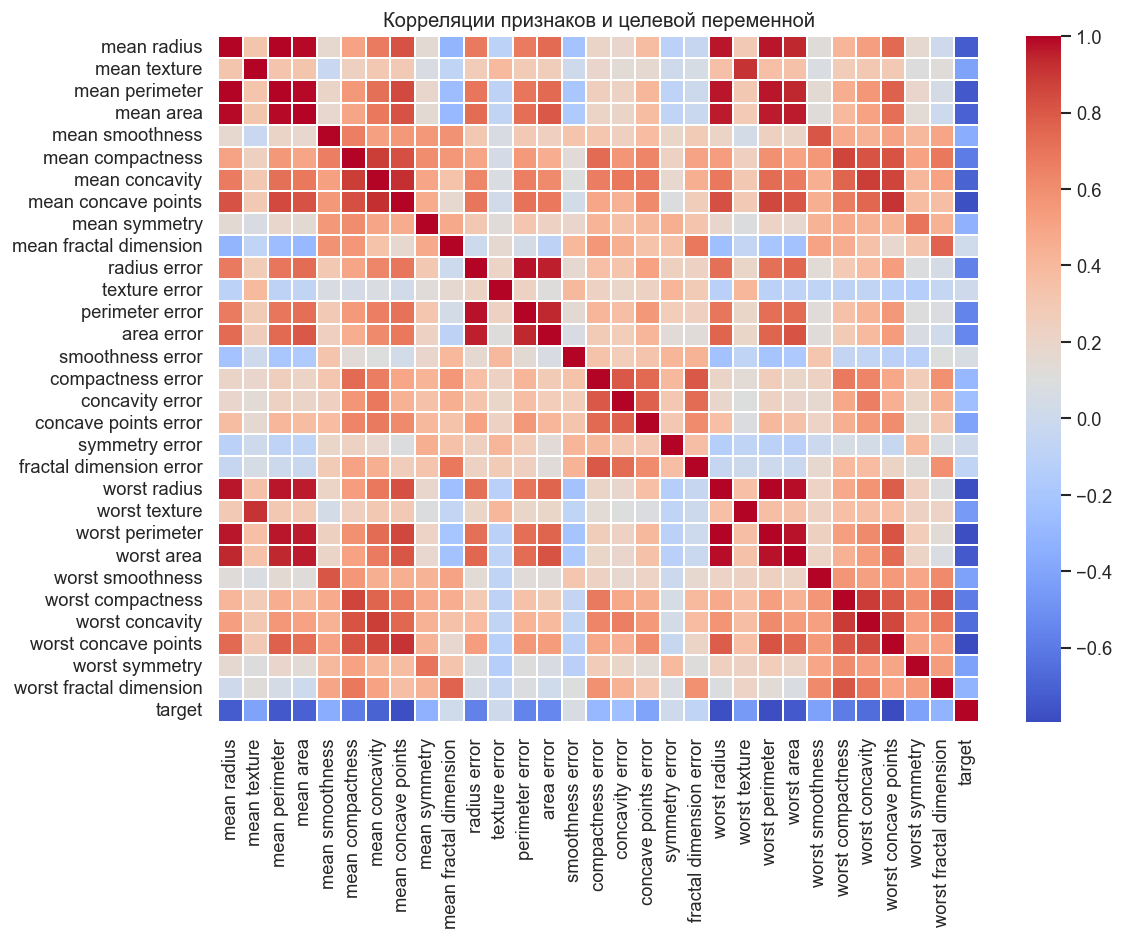
Тепловая карта корреляций¶
Матрица из 31 переменной. Нейросеть, в отличие от линейных моделей, не страдает от мультиколлинеарности — она сама учится находить нужные комбинации признаков. Тем не менее тепловая карта помогает понять структуру данных и выбрать число нейронов.
plt.figure(figsize=(10, 8))
correlation = data.corr()
sns.heatmap(correlation, cmap=HEATMAP_CMAP, linewidths=0.2)
plt.title("Корреляции признаков и целевой переменной")
plt.tight_layout()
plt.show()
Обучение модели¶
MLPClassifier(hidden_layer_sizes=(64, 32)) — два скрытых слоя с 64 и 32 нейронами и активацией ReLU. max_iter=500 — максимальное число эпох. Используем оптимизатор Adam (по умолчанию solver='adam'). Нейросеть обучается итерационно, постепенно уменьшая кросс-энтропийные потери через backpropagation.
model = Pipeline(
steps=[
("scaler", StandardScaler()),
("mlp", MLPClassifier(
hidden_layer_sizes=(64, 32),
activation="relu",
max_iter=500,
random_state=42,
)),
]
)
model.fit(X_train, y_train)
Прогнозы модели¶
Метрики на тестовой выборке:
Accuracy — ожидаем >97% для нейросети на этом датасете;
Precision/Recall/F1 — важны особенно для FN (пропущенные злокачественные случаи).
Нейросеть должна превзойти одиночное дерево решений и быть сравнима с Random Forest.
y_pred = model.predict(X_test)
print("MLP Classifier Metrics")
print(f"Accuracy: {accuracy_score(y_test, y_pred):.3f}")
print(f"Precision: {precision_score(y_test, y_pred):.3f}")
print(f"Recall: {recall_score(y_test, y_pred):.3f}")
print(f"F1: {f1_score(y_test, y_pred):.3f}")
MLP Classifier Metrics
Accuracy: 0.965
Precision: 0.986
Recall: 0.958
F1: 0.972
Графики выходных результатов¶
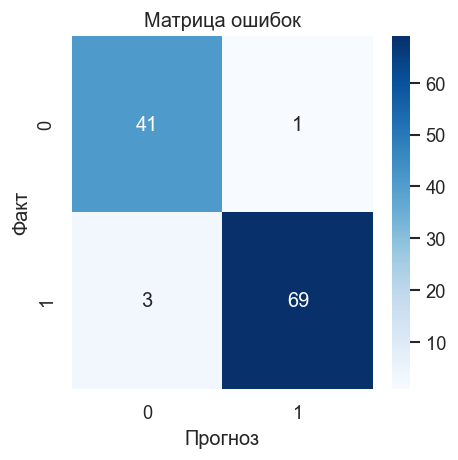
График 1. Матрица ошибок. Ожидаем минимальные внедиагональные значения. FN (правый нижний — предсказан доброкачественный, реально злокачественный) — наиболее критичная ошибка.
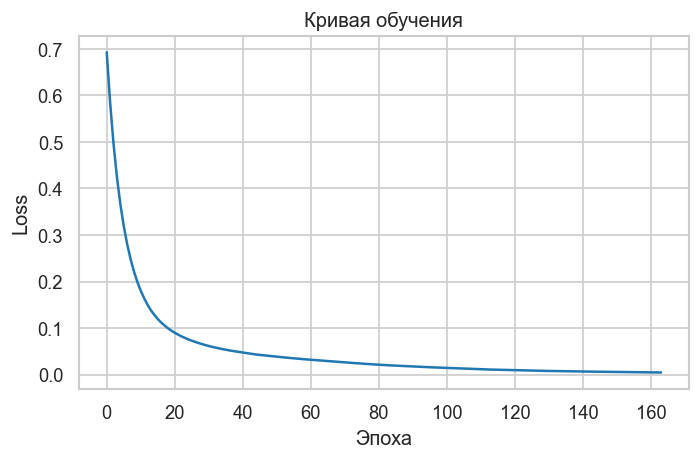
График 2. Кривая обучения (Loss Curve). Показывает, как снижается кросс-энтропия по эпохам. Монотонное убывание — нормальная сходимость. Плато указывает, что модель остановилась; «пила» означает слишком большой learning rate. Число итераций, при котором кривая выравнивается, — ориентир для max_iter.
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(4, 4))
sns.heatmap(cm, annot=True, fmt="d", cmap=CONFUSION_CMAP)
plt.title("Матрица ошибок")
plt.xlabel("Прогноз")
plt.ylabel("Факт")
plt.tight_layout()
plt.show()
loss_curve = model.named_steps["mlp"].loss_curve_
plt.figure(figsize=(6, 4))
plt.plot(loss_curve, color=PRIMARY_COLOR)
plt.xlabel("Эпоха")
plt.ylabel("Loss")
plt.title("Кривая обучения")
plt.tight_layout()
plt.show()