Линейная регрессия моделирует зависимость цели от признаков как . Оценки коэффициентов находятся из задачи минимизации суммы квадратов ошибок: . В матричной форме решение (при обратимости) задается , а качество обычно оценивают по MAE, RMSE и .
Используемые библиотеки¶
Подключаем стандартные библиотеки для работы с данными (numpy, pandas), визуализации (seaborn, matplotlib) и инструменты sklearn для загрузки данных, масштабирования, построения пайплайна и метрик.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
import warnings
warnings.filterwarnings("ignore")
sns.set_theme(style="whitegrid", palette="deep")
plt.rcParams["figure.dpi"] = 120
PRIMARY_COLOR = "#1f77b4"
SECONDARY_COLOR = "#ff7f0e"
HEATMAP_CMAP = "coolwarm"
Датасет: описание и частичная распечатка¶
Датасет California Housing из sklearn содержит 20 640 блоков переписи населения Калифорнии 1990 года. Каждый объект — усредненные характеристики блока: медианный доход, возраст домов, число комнат, число спален, население, число домохозяйств, широта и долгота. Целевая переменная — MedHouseVal: медианная стоимость дома в блоке (в $100 000). Задача — регрессия: предсказать цену по 8 числовым признакам.
housing = fetch_california_housing(as_frame=True)
data = housing.frame
print(f"Размерность: {data.shape}")
data.head()
Размерность: (20640, 9)
Предварительная обработка¶
Удаляем строки с пропусками (датасет чистый, но привычка хорошая). Отделяем матрицу признаков X от целевой переменной y. Разбиваем данные на обучающую (80%) и тестовую (20%) выборки с фиксированным random_state=42 для воспроизводимости. Масштабирование выполняется внутри пайплайна — это гарантирует, что параметры StandardScaler вычислены только на обучающих данных.
features = data.drop(columns=["MedHouseVal"])
target = data["MedHouseVal"]
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.2, random_state=42
)
Тепловая карта корреляций¶
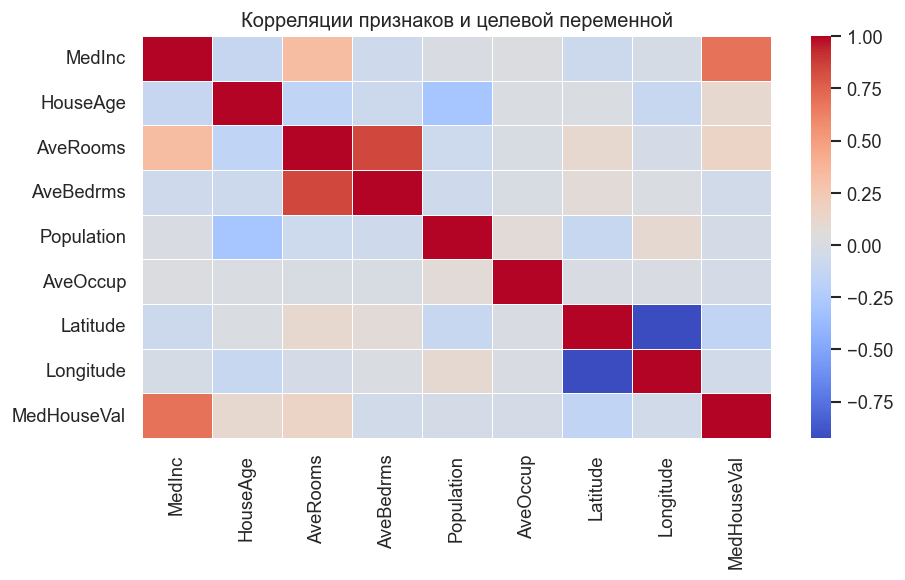
Строим матрицу коэффициентов Пирсона. Значения близкие к +1 (темно-красные) указывают на сильную прямую зависимость, близкие к −1 (темно-синие) — на обратную. Обратите внимание, что MedInc (медианный доход) имеет наибольшую положительную корреляцию с целевой переменной — это ключевой предиктор. Признаки Latitude/Longitude имеют заметную отрицательную корреляцию: цены падают с удалением от побережья.
plt.figure(figsize=(8, 5))
correlation = data.corr()
sns.heatmap(correlation, annot=False, cmap=HEATMAP_CMAP, linewidths=0.5)
plt.title("Корреляции признаков и целевой переменной")
plt.tight_layout()
plt.show()
Обучение модели¶
Строим Pipeline из двух шагов: StandardScaler масштабирует признаки до нулевого среднего и единичной дисперсии, LinearRegression подбирает оптимальные веса методом МНК. Пайплайн удобен: трансформер fit_transform на X_train и только transform на X_test, что исключает утечку данных.
model = Pipeline(
steps=[
("scaler", StandardScaler()),
("regressor", LinearRegression()),
]
)
model.fit(X_train, y_train)
Прогнозы модели¶
Оцениваем модель на тестовой выборке тремя метриками:
MAE — среднее абсолютное отклонение в $100 000;
RMSE — среднеквадратическое отклонение, чувствительное к выбросам;
R² — доля объясненной дисперсии (1.0 = идеальный прогноз, 0 = модель не лучше среднего).
y_pred = model.predict(X_test)
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
r2 = r2_score(y_test, y_pred)
print("Linear Regression Metrics")
print(f"MAE: {mae:.3f}")
print(f"RMSE: {rmse:.3f}")
print(f"R2: {r2:.3f}")
Linear Regression Metrics
MAE: 0.533
RMSE: 0.746
R2: 0.576
Графики выходных результатов¶
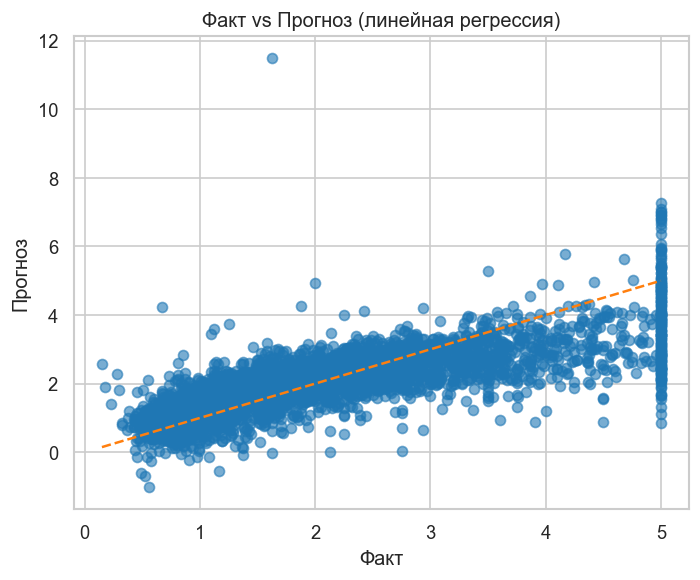
График 1. Факт vs Прогноз. Точки вдоль красной диагонали — идеальный прогноз. Отклонения вверх означают завышение, вниз — занижение. Заметна систематическая ошибка при высоких ценах (>4): модель их недооценивает — нелинейный эффект «потолка» цен.
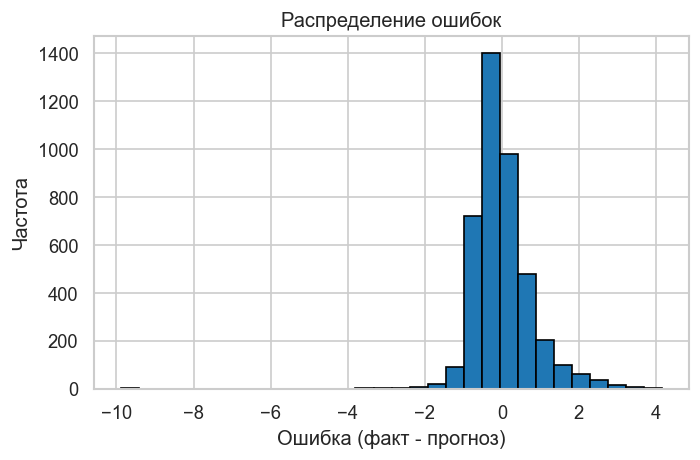
График 2. Распределение ошибок. Гистограмма остатков должна быть симметричной и близкой к нормальной — это условие эффективности МНК. Выраженный скос или тяжёлые хвосты указывают на нелинейность или выбросы.
plt.figure(figsize=(6, 5))
plt.scatter(y_test, y_pred, alpha=0.6, color=PRIMARY_COLOR)
plt.plot(
[y_test.min(), y_test.max()],
[y_test.min(), y_test.max()],
color=SECONDARY_COLOR,
linestyle="--",
)
plt.xlabel("Факт")
plt.ylabel("Прогноз")
plt.title("Факт vs Прогноз (линейная регрессия)")
plt.tight_layout()
plt.show()
residuals = y_test - y_pred
plt.figure(figsize=(6, 4))
plt.hist(residuals, bins=30, edgecolor="black", color=PRIMARY_COLOR)
plt.xlabel("Ошибка (факт - прогноз)")
plt.ylabel("Частота")
plt.title("Распределение ошибок")
plt.tight_layout()
plt.show()