Наивный Байес использует теорему Байеса: . Предполагается условная независимость признаков, поэтому . В случае GaussianNB каждый признак моделируется нормальным распределением . На практике важен гиперпараметр var_smoothing: он добавляет маленькую стабилизирующую константу к оценкам дисперсий и может заметно улучшить качество на более сложных данных.
Используемые библиотеки¶
Используем numpy, pandas, seaborn, matplotlib. Из sklearn — датасет load_digits, train_test_split, StratifiedKFold, GridSearchCV, Pipeline, GaussianNB и метрики классификации.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split, StratifiedKFold, GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
sns.set_theme(style="whitegrid", palette="deep")
plt.rcParams["figure.dpi"] = 120
PRIMARY_COLOR = "#1f77b4"
HEATMAP_CMAP = "coolwarm"
CONFUSION_CMAP = "Blues"
Датасет: описание и частичная распечатка¶
Датасет Digits из sklearn заметно сложнее, чем Iris: 1797 изображений рукописных цифр от 0 до 9, каждое изображение представлено матрицей 8×8 пикселей (64 числовых признака). Это уже 10-классовая задача классификации с более высокой размерностью и похожими между собой классами, поэтому она лучше подходит для демонстрации ограничений и сильных сторон наивного Байеса.
digits = load_digits(as_frame=True)
data = digits.frame
print(f"Размерность: {data.shape}")
data.head()
Размерность: (1797, 65)
fig, axes = plt.subplots(2, 5, figsize=(8, 4))
for ax, image, label in zip(axes.ravel(), digits.images[:10], digits.target[:10]):
ax.imshow(image, cmap="gray_r")
ax.set_title(f"Цифра {label}")
ax.axis("off")
plt.suptitle("Примеры изображений из Digits")
plt.tight_layout()
plt.show()

Предварительная обработка¶
Отделяем признаки от целевой переменной и разбиваем выборку на train/test (80/20) со стратификацией. Масштабирование для GaussianNB не обязательно: модель отдельно оценивает средние и дисперсии признаков внутри каждого класса. Подбор гиперпараметров будем выполнять только на обучающей части, чтобы не допускать утечки данных.
features = data.drop(columns=["target"])
target = data["target"]
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.2, random_state=42, stratify=target
)
Тепловая карта корреляций¶
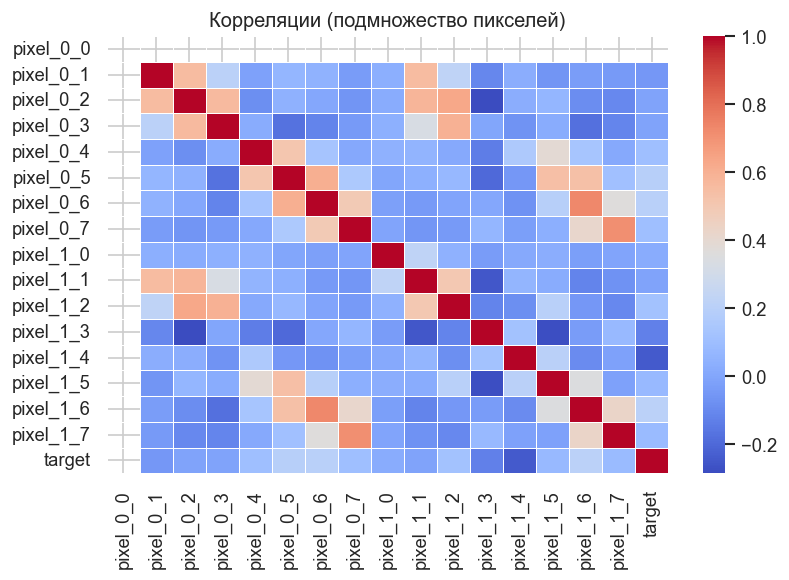
Полная корреляционная матрица для 64 пикселей была бы слишком громоздкой, поэтому возьмём первые 16 признаков. Уже здесь видно, что пиксели не являются независимыми — это нарушает базовое предположение наивного Байеса, но модель всё равно часто работает удивительно хорошо на практике.
plt.figure(figsize=(7, 5))
subset_cols = features.columns[:16]
correlation = data[list(subset_cols) + ["target"]].corr()
sns.heatmap(correlation, annot=False, cmap=HEATMAP_CMAP, linewidths=0.3)
plt.title("Корреляции (подмножество пикселей)")
plt.tight_layout()
plt.show()
Подбор гиперпараметров¶
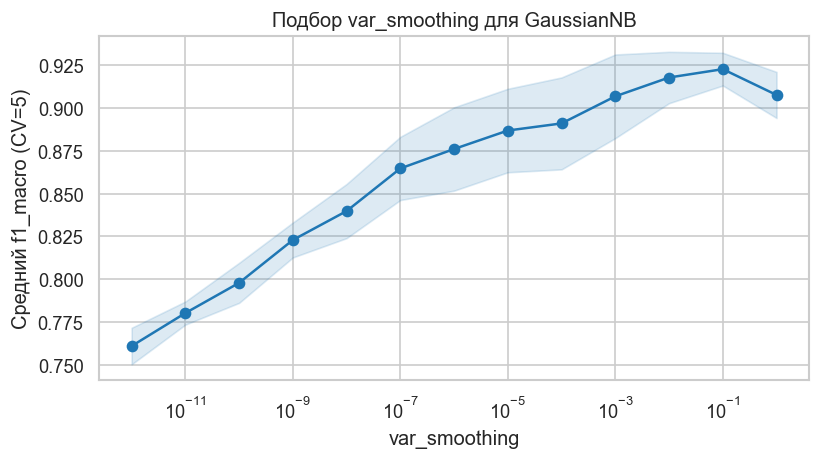
У GaussianNB мало настраиваемых параметров, но var_smoothing часто влияет на устойчивость модели. Проверим логарифмическую сетку значений от 10-12 до 100 на кросс-валидации StratifiedKFold. Оптимизируем метрику f1_macro, чтобы качество оценивалось равномерно по всем 10 классам.
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
nb_pipeline = Pipeline(
steps=[
("nb", GaussianNB()),
]
)
param_grid = {
"nb__var_smoothing": np.logspace(-12, 0, 13),
}
grid = GridSearchCV(
nb_pipeline,
param_grid=param_grid,
cv=cv,
scoring="f1_macro",
n_jobs=-1,
refit=True,
)
grid.fit(X_train, y_train)
cv_results = (
pd.DataFrame(grid.cv_results_)[["param_nb__var_smoothing", "mean_test_score", "std_test_score"]]
.rename(columns={"param_nb__var_smoothing": "var_smoothing"})
)
cv_results["var_smoothing"] = cv_results["var_smoothing"].astype(float)
cv_results = cv_results.sort_values("var_smoothing")
print("Лучшие параметры по CV")
print(grid.best_params_)
print(f"Best CV f1_macro: {grid.best_score_:.3f}")
cv_results
Лучшие параметры по CV
{'nb__var_smoothing': np.float64(0.1)}
Best CV f1_macro: 0.923
plt.figure(figsize=(7, 4))
plt.semilogx(cv_results["var_smoothing"], cv_results["mean_test_score"], marker="o", color=PRIMARY_COLOR)
plt.fill_between(
cv_results["var_smoothing"],
cv_results["mean_test_score"] - cv_results["std_test_score"],
cv_results["mean_test_score"] + cv_results["std_test_score"],
color=PRIMARY_COLOR,
alpha=0.15,
)
plt.xlabel("var_smoothing")
plt.ylabel("Средний f1_macro (CV=5)")
plt.title("Подбор var_smoothing для GaussianNB")
plt.tight_layout()
plt.show()
Обучение модели¶
Используем лучшую конфигурацию, найденную на кросс-валидации, и обучаем её на всей обучающей выборке.
best_model = grid.best_estimator_
best_model.fit(X_train, y_train)
model = best_model
Прогнозы модели¶
На тестовой выборке посмотрим несколько метрик:
Accuracy — общая доля верных предсказаний;
Precision/Recall/F1 weighted — учитывают размеры классов;
F1 macro — особенно полезна здесь, потому что мы подбирали параметры по равномерному качеству на всех цифрах.
y_pred = model.predict(X_test)
print("Gaussian Naive Bayes Metrics")
print(f"Accuracy: {accuracy_score(y_test, y_pred):.3f}")
print(f"Precision: {precision_score(y_test, y_pred, average='weighted', zero_division=0):.3f}")
print(f"Recall: {recall_score(y_test, y_pred, average='weighted', zero_division=0):.3f}")
print(f"F1 weighted: {f1_score(y_test, y_pred, average='weighted', zero_division=0):.3f}")
print(f"F1 macro: {f1_score(y_test, y_pred, average='macro', zero_division=0):.3f}")
Gaussian Naive Bayes Metrics
Accuracy: 0.922
Precision: 0.923
Recall: 0.922
F1 weighted: 0.922
F1 macro: 0.921
Графики выходных результатов¶
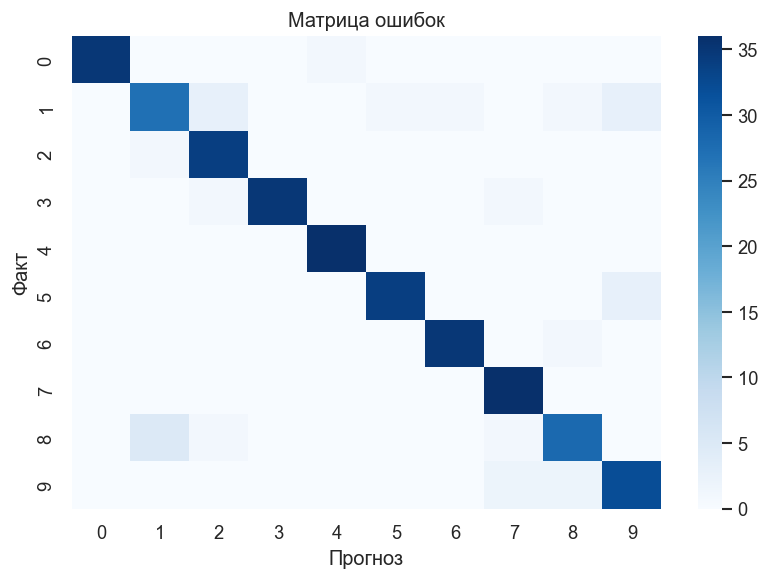
График 1. Матрица ошибок 10×10. На диагонали — верные предсказания. Вне диагонали будут пары цифр, которые модель чаще путает из-за визуального сходства.
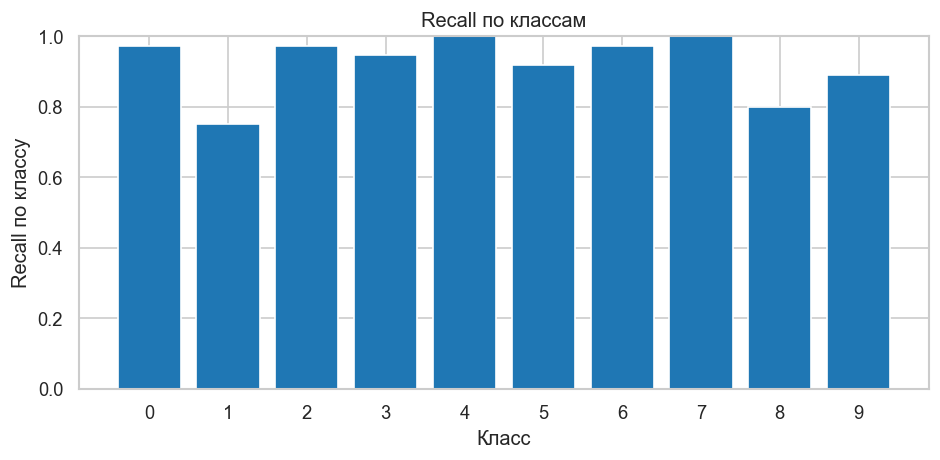
График 2. Recall по классам. Это доля объектов каждого истинного класса, распознанных правильно. График помогает быстро увидеть, какие цифры особенно сложны для GaussianNB.
cm = confusion_matrix(y_test, y_pred)
class_names = [str(name) for name in digits.target_names]
plt.figure(figsize=(7, 5))
sns.heatmap(cm, annot=False, cmap=CONFUSION_CMAP, xticklabels=class_names, yticklabels=class_names)
plt.title("Матрица ошибок")
plt.xlabel("Прогноз")
plt.ylabel("Факт")
plt.tight_layout()
plt.show()
per_class_recall = []
for cls in np.unique(y_test):
mask = y_test == cls
per_class_recall.append(np.mean(y_pred[mask] == y_test[mask]))
plt.figure(figsize=(8, 4))
plt.bar(class_names, per_class_recall, color=PRIMARY_COLOR)
plt.ylim(0, 1)
plt.ylabel("Recall по классу")
plt.xlabel("Класс")
plt.title("Recall по классам")
plt.tight_layout()
plt.show()