Метод KNN относит объект к классу, наиболее частому среди ближайших соседей по выбранной метрике расстояния, например Евклидовой: . Класс вычисляется по голосованию: . Для регрессии используют среднее по соседям. Масштабирование признаков важно, так как расстояния чувствительны к масштабам.
Используемые библиотеки¶
Используем numpy, pandas, seaborn, matplotlib. Из sklearn — load_wine, train_test_split, StandardScaler, Pipeline, KNeighborsClassifier, StratifiedKFold, cross_val_score и метрики классификации.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split, StratifiedKFold, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
sns.set_theme(style="whitegrid", palette="deep")
plt.rcParams["figure.dpi"] = 120
PRIMARY_COLOR = "#1f77b4"
HEATMAP_CMAP = "coolwarm"
CONFUSION_CMAP = "Blues"
Датасет: описание и частичная распечатка¶
Датасет Wine — результаты химического анализа 178 вин из трёх сортов винограда Италии. 13 числовых признаков: алкоголь, яблочная кислота, зола, магний, фенолы, флавоноиды, пролин и т.д. Целевая переменная — сорт вина (0, 1, 2). Задача — мультиклассовая классификация. Признаки имеют разные масштабы (алкоголь ~12, пролин ~700), поэтому стандартизация необходима для KNN.
wine = load_wine(as_frame=True)
data = wine.frame
print(f"Размерность: {data.shape}")
data.head()
Размерность: (178, 14)
Предварительная обработка¶
Разделяем признаки и целевую переменную. Разбиваем на train/test со стратификацией. StandardScaler внутри Pipeline приводит все признаки к шкале с нулевым средним и единичной дисперсией — это устраняет доминирование признаков с большими абсолютными значениями при вычислении расстояний.
features = data.drop(columns=["target"])
target = data["target"]
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.2, random_state=42, stratify=target
)
Тепловая карта корреляций¶
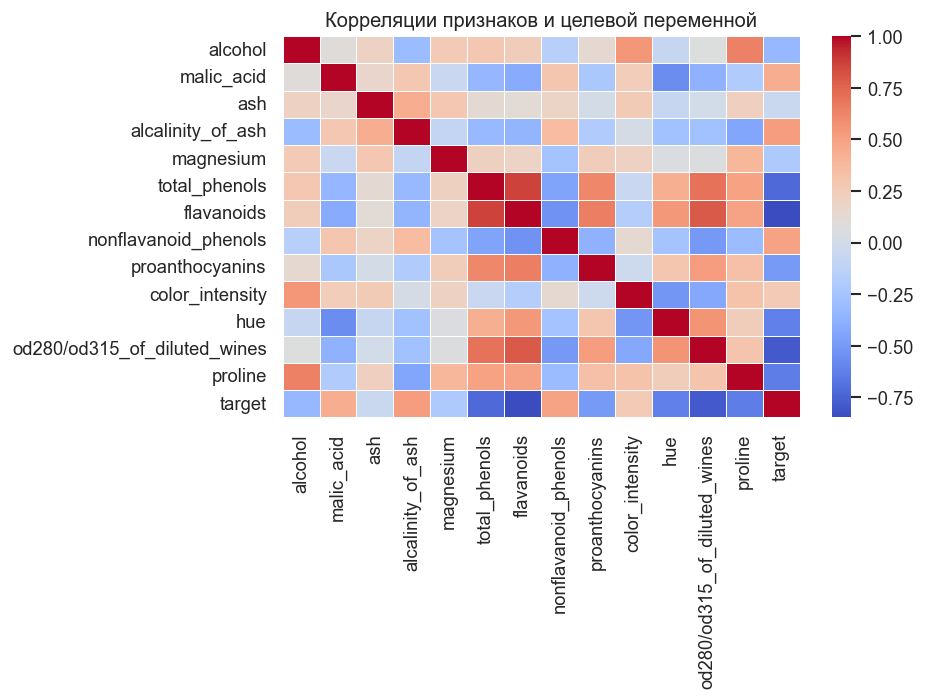
Матрица из 14 переменных. Заметна высокая корреляция флавоноидов с фенолами и пролина с алкоголем. KNN не предполагает линейную зависимость между признаками, но мультиколлинеарность может затруднять выбор оптимального — коррелирующие признаки «дублируют» информацию в метрике расстояния.
plt.figure(figsize=(8, 6))
correlation = data.corr()
sns.heatmap(correlation, annot=False, cmap=HEATMAP_CMAP, linewidths=0.3)
plt.title("Корреляции признаков и целевой переменной")
plt.tight_layout()
plt.show()
Обоснование выбора ¶
Подберем по кросс-валидации: для каждого нечётного измерим среднюю accuracy на 5 фолдах. Нечётные значения уменьшают вероятность «ничьи» в голосовании. Обычно малые переобучаются, большие — недообучаются; график помогает найти разумный компромисс.
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
k_values = list(range(1, 26, 2))
cv_scores = []
for k in k_values:
cv_model = Pipeline(
steps=[
("scaler", StandardScaler()),
("knn", KNeighborsClassifier(n_neighbors=k)),
]
)
scores = cross_val_score(cv_model, X_train, y_train, cv=cv, scoring="accuracy")
cv_scores.append(scores.mean())
best_idx = int(np.argmax(cv_scores))
best_k = k_values[best_idx]
plt.figure(figsize=(6, 4))
plt.plot(k_values, cv_scores, marker="o", color=PRIMARY_COLOR)
plt.axvline(best_k, color="gray", linestyle="--", linewidth=1)
plt.title("Подбор k по кросс-валидации")
plt.xlabel("k")
plt.ylabel("Средняя accuracy (CV=5)")
plt.tight_layout()
plt.show()
print(f"Лучшее k по CV: {best_k} (accuracy={cv_scores[best_idx]:.3f})")
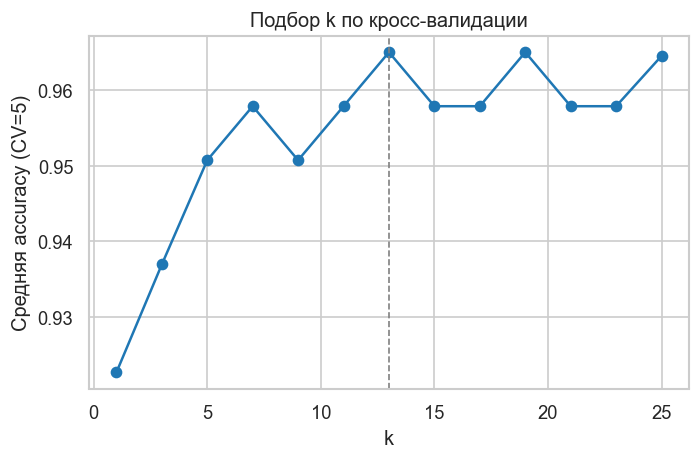
Лучшее k по CV: 13 (accuracy=0.965)
Обучение модели¶
Pipeline из StandardScaler и KNeighborsClassifier(n_neighbors=best_k). Используем , выбранное по кросс-валидации на обучающей выборке.
model = Pipeline(
steps=[
("scaler", StandardScaler()),
("knn", KNeighborsClassifier(n_neighbors=best_k)),
]
)
model.fit(X_train, y_train)
Прогнозы модели¶
Вычисляем метрики с усреднением weighted:
Accuracy — общая точность;
Precision/Recall/F1 — взвешенные по размеру классов.
KNN с подобранным обычно дает хорошие результаты на Iris/Wine-подобных датасетах с хорошо разделёнными кластерами.
y_pred = model.predict(X_test)
print("KNN Metrics")
print(f"Accuracy: {accuracy_score(y_test, y_pred):.3f}")
print(f"Precision: {precision_score(y_test, y_pred, average='weighted'):.3f}")
print(f"Recall: {recall_score(y_test, y_pred, average='weighted'):.3f}")
print(f"F1: {f1_score(y_test, y_pred, average='weighted'):.3f}")
KNN Metrics
Accuracy: 1.000
Precision: 1.000
Recall: 1.000
F1: 1.000
Графики выходных результатов¶
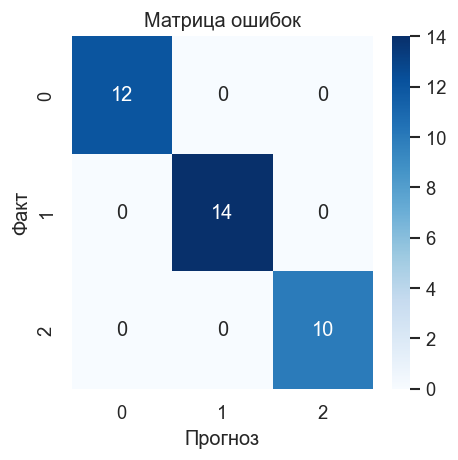
График 1. Матрица ошибок. Показывает систематические ошибки: какие сорта чаще путаются. KNN чувствителен к выбросам — единственный неверно классифицированный образец может дать «полосу» ошибок.
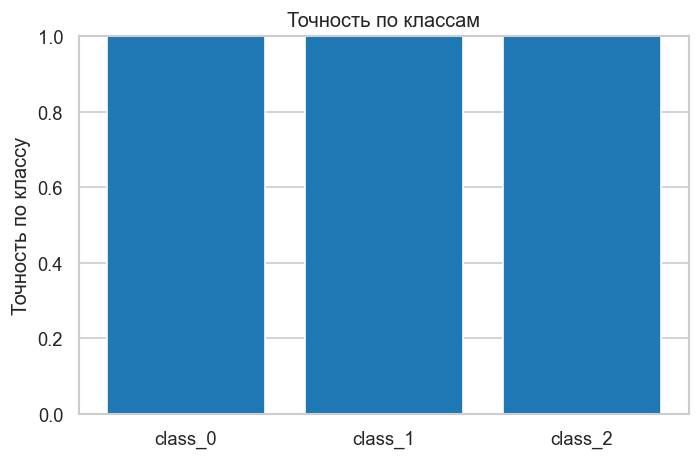
График 2. Точность по классам. Позволяет оценить сбалансированность качества: если один класс значительно хуже других, стоит проверить его представительность в обучающей выборке или подобрать другое .
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(4, 4))
sns.heatmap(cm, annot=True, fmt="d", cmap=CONFUSION_CMAP)
plt.title("Матрица ошибок")
plt.xlabel("Прогноз")
plt.ylabel("Факт")
plt.tight_layout()
plt.show()
class_names = wine.target_names
per_class_acc = []
for cls in np.unique(y_test):
mask = y_test == cls
per_class_acc.append(np.mean(y_pred[mask] == y_test[mask]))
plt.figure(figsize=(6, 4))
plt.bar(class_names, per_class_acc, color=PRIMARY_COLOR)
plt.ylim(0, 1)
plt.ylabel("Точность по классу")
plt.title("Точность по классам")
plt.tight_layout()
plt.show()