SVM ищет разделяющую гиперплоскость с максимальным зазором: при ограничениях . Для мягкого зазора вводят штраф и переменные ошибок: . Нелинейное разделение достигается через ядро (например RBF). Предсказание: .
Используемые библиотеки¶
Используем numpy, pandas, seaborn, matplotlib. Из sklearn — load_digits, train_test_split, StandardScaler, Pipeline, SVC, StratifiedKFold, GridSearchCV и метрики классификации.
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split, StratifiedKFold, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score, confusion_matrix
sns.set_theme(style="whitegrid", palette="deep")
plt.rcParams["figure.dpi"] = 120
PRIMARY_COLOR = "#1f77b4"
HEATMAP_CMAP = "coolwarm"
CONFUSION_CMAP = "Blues"
Датасет: описание и частичная распечатка¶
Датасет Digits из sklearn — 1797 изображений рукописных цифр (0–9) в виде матриц 8×8 пикселей (64 признака). Это задача мультиклассовой классификации (10 классов) с высокой размерностью признаков. Классы сбалансированы (~180 примеров каждый). SVM с RBF-ядром исторически являлся одним из лучших методов для распознавания рукописных цифр до эпохи глубокого обучения.
digits = load_digits(as_frame=True)
data = digits.frame
print(f"Размерность: {data.shape}")
data.head()
Размерность: (1797, 65)
Предварительная обработка¶
Разделяем признаки (64 пиксельных значения) и метку. Разбиваем на train/test со стратификацией. StandardScaler критически важен для SVM: ядро RBF вычисляет , и без нормировки признаки с большим диапазоном значений доминируют над остальными, что искажает геометрию пространства.
features = data.drop(columns=["target"])
target = data["target"]
X_train, X_test, y_train, y_test = train_test_split(
features, target, test_size=0.2, random_state=42, stratify=target
)
Тепловая карта корреляций¶
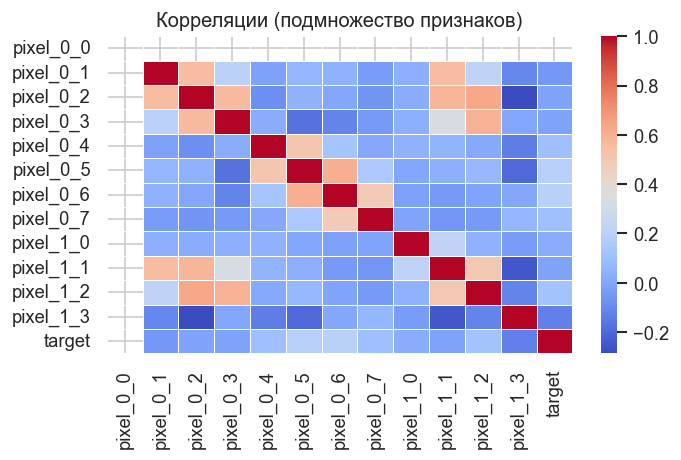
Берём подмножество из первых 12 пиксельных признаков для наглядности. Соседние пиксели на изображении коррелируют — пространственная структура данных отражается в тепловой карте. Полная матрица из 64 признаков была бы малочитаемой, но паттерн тот же.
plt.figure(figsize=(6, 4))
subset_cols = features.columns[:12]
correlation = data[list(subset_cols) + ["target"]].corr()
sns.heatmap(correlation, annot=False, cmap=HEATMAP_CMAP, linewidths=0.3)
plt.title("Корреляции (подмножество признаков)")
plt.tight_layout()
plt.show()
Сравнение ядер SVM¶
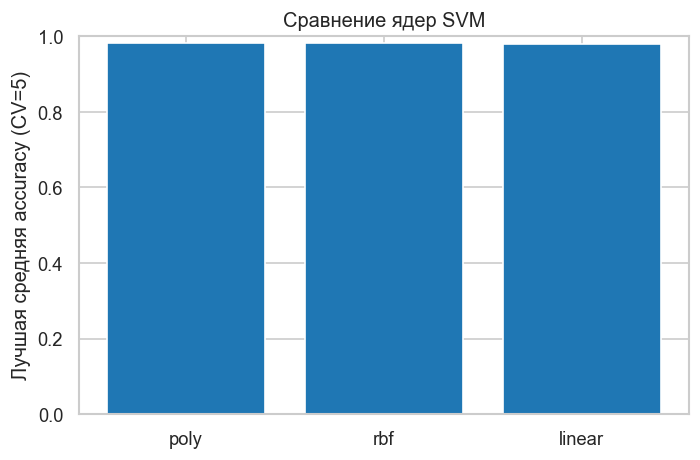
Проверим разные ядра на кросс-валидации. Для linear подбираем только C, для rbf — C и gamma, для poly — C и степень полинома. Оцениваем по accuracy.
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
svm_pipeline = Pipeline(
steps=[
("scaler", StandardScaler()),
("svm", SVC()),
]
)
param_grid = [
{"svm__kernel": ["linear"], "svm__C": [0.1, 1, 10]},
{
"svm__kernel": ["rbf"],
"svm__C": [0.1, 1, 10],
"svm__gamma": ["scale", 0.01, 0.1, 1],
},
{
"svm__kernel": ["poly"],
"svm__C": [0.1, 1, 10],
"svm__degree": [2, 3],
"svm__gamma": ["scale"],
},
]
grid = GridSearchCV(
svm_pipeline,
param_grid=param_grid,
cv=cv,
scoring="accuracy",
n_jobs=-1,
)
grid.fit(X_train, y_train)
results = pd.DataFrame(grid.cv_results_)
summary = (
results.groupby("param_svm__kernel")["mean_test_score"]
.max()
.sort_values(ascending=False)
)
plt.figure(figsize=(6, 4))
plt.bar(summary.index, summary.values, color=PRIMARY_COLOR)
plt.ylim(0, 1)
plt.ylabel("Лучшая средняя accuracy (CV=5)")
plt.title("Сравнение ядер SVM")
plt.tight_layout()
plt.show()
print("Лучшие параметры по CV")
print(grid.best_params_)
print(f"Best CV accuracy: {grid.best_score_:.3f}")
Лучшие параметры по CV
{'svm__C': 10, 'svm__degree': 3, 'svm__gamma': 'scale', 'svm__kernel': 'poly'}
Best CV accuracy: 0.983
Обучение модели¶
Используем лучшую конфигурацию из кросс-валидации и обучаем её на всей обучающей выборке.
best_model = grid.best_estimator_
best_model.fit(X_train, y_train)
model = best_model
Прогнозы модели¶
Метрики с усреднением weighted для 10 классов:
Accuracy обычно высокая на Digits для корректно настроенного SVM;
Precision/Recall/F1 — показывают, какие цифры распознаются хуже (часто путают 1↔7, 3↔5, 4↔9).
y_pred = model.predict(X_test)
print("SVM Metrics")
print(f"Accuracy: {accuracy_score(y_test, y_pred):.3f}")
print(f"Precision: {precision_score(y_test, y_pred, average='weighted'):.3f}")
print(f"Recall: {recall_score(y_test, y_pred, average='weighted'):.3f}")
print(f"F1: {f1_score(y_test, y_pred, average='weighted'):.3f}")
SVM Metrics
Accuracy: 0.994
Precision: 0.995
Recall: 0.994
F1: 0.994
Графики выходных результатов¶
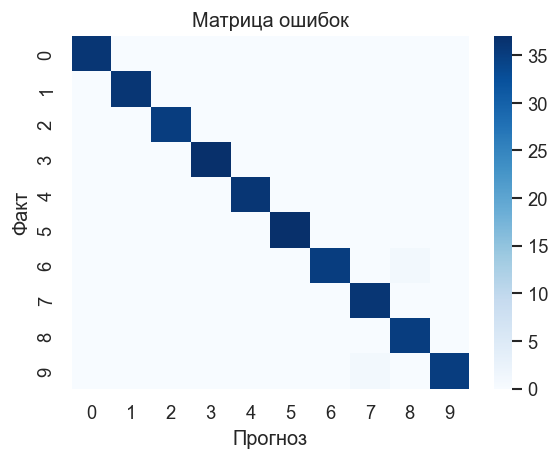
График 1. Матрица ошибок 10×10. Диагональ должна быть тёмно-синей. Ярко выделенные внедиагональные ячейки указывают на систематически путаемые пары цифр — визуально похожие символы.
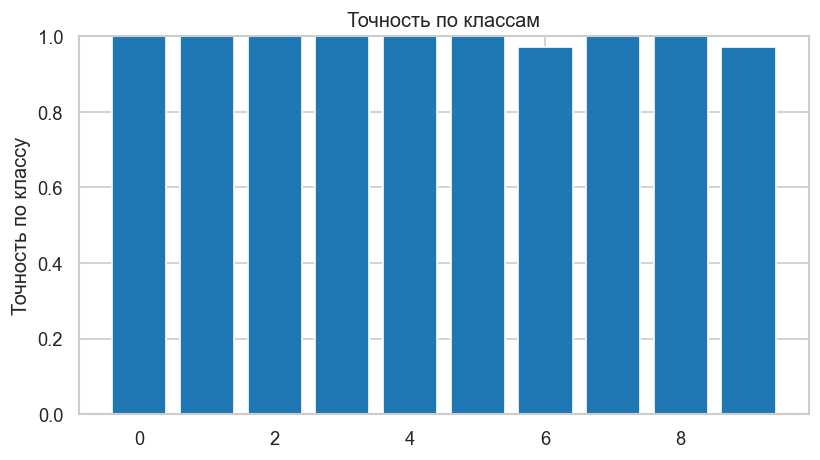
График 2. Точность по классам. Почти все цифры должны распознаваться с точностью близкой к 1.0. Отклонения укажут, какие классы сложнее для SVM при данной конфигурации ядра.
cm = confusion_matrix(y_test, y_pred)
plt.figure(figsize=(5, 4))
sns.heatmap(cm, annot=False, cmap=CONFUSION_CMAP)
plt.title("Матрица ошибок")
plt.xlabel("Прогноз")
plt.ylabel("Факт")
plt.tight_layout()
plt.show()
class_names = digits.target_names
per_class_acc = []
for cls in np.unique(y_test):
mask = y_test == cls
per_class_acc.append(np.mean(y_pred[mask] == y_test[mask]))
plt.figure(figsize=(7, 4))
plt.bar(class_names, per_class_acc, color=PRIMARY_COLOR)
plt.ylim(0, 1)
plt.ylabel("Точность по классу")
plt.title("Точность по классам")
plt.tight_layout()
plt.show()