Разработка и применение программного обеспечения в физических исследованиях
Вячеслав Федоров, ИЯФ СО РАН
Для студентов физических специальностей и начинающих ИТ-специалистов, которые хотят познакомиться с Python, Linux, DevOps и SRE.
Цель этой книги — помочь тебе научиться писать более красивые, надёжные и легко сопровождаемые программы для физических исследований. То, о чём мы здесь будем говорить, это не начальный уровень, предполагается, что ты уже знаешь основы физики, минимально умеешь программировать, и хочешь научиться делать это лучше.
И это — отличная цель, к которой мы вместе будем двигаться!
Часто на физических факультетах не уделяется должного внимания IT-дисциплинам, в то время как они очень важны и могут значительно улучшить качество твоих исследований.
В ревью кода моих коллег часто видны результаты того, что в учебных материалах не уделяется отдельное внимание вопросам качества кода. Качество программы и её надёжность страдают — а это гораздо более важные параметры, чем многие поначалу думают. Поначалу кажется, что я написал программу, она в моих идеальных условиях работает и этого достаточно. Но нет, этого недостаточно. Наличие функциональности это одно, а надёжность этой функциональности и качество реализации этой функциональности это совсем другое. То, что мы написали программу и она имеет функциональность — это вовсе не означает, что программа действительно хороша. В этой небольшой книге мы поговорим о том, как разрабатывать, думая не только о функциональности, но и о качестве и надёжности её реализации.
Цели книги:
- Познакомиться с основами Linux: Изучить архитектуру операционной системы GNU/Linux, файловые системы, процессы загрузки и методы управления дисками.
- Освоить Python: Погрузиться в мир программирования на Python, изучить синтаксис, использование интерактивной оболочки IPython и применять язык для решения физических задач.
- Изучить DevOps и SRE: Разобраться в жизненном цикле программного обеспечения, управлении версиями, автоматизации процессов разработки и обеспечения надежности систем.
- Научиться работать с базами данных: Понять различные системы управления базами данных (СУБД) и их применение в реальных проектах.
- Освоить инструменты для обработки и анализа данных: Изучить библиотеки NumPy, SciPy, Pandas, Matplotlib и другие для эффективного анализа больших данных.
- Погрузиться в машинное обучение и нейронные сети: Изучить базовые алгоритмы классификации и основы работы с нейронными сетями для обработки данных физических экспериментов.
- Оптимизировать производительность программ: Научиться измерять время выполнения кода, использовать параллельные вычисления и работать с GPU для ускорения обработки данных.
О себе
Меня зовут Федоров Вячеслав Васильевич, я разработчик программного обеспечения с глубокими знаниями в области физики и вычислительной математики. На протяжении нескольких лет я работаю в Институте ядерной физики им. Будкера, где занимаюсь разработкой наукоемкого прикладного программного обеспечения на языках высокого уровня Python и C++ для решения различных задач. Моя основная работа сосредоточена на моделировании динамики заряженных частиц в сложных электромагнитных полях, а также на внедрении алгоритмов машинного обучения для оптимизации и настройки ускорительных комплексов.
Мой опыт также включает работу в международной компании по разработке ПО и веб-приложений SIBERS, где я руководил командой разработчиков в создании ПО на основе микросервисной архитектуры для государственной организации, оказывающей финансовые услуги. Я активно участвовал в разработке дополнительных модулей для статического анализа кода для различных сред разработки, а также был ведущим разработчиком приложения для врачей, предназначенного для распознавания и присвоения кодов болезней в медицинских картах пациентов с использованием бессерверных вычислений и алгоритмов машинного обучения. Я внедрял процессы автоматизированного тестирования, непрерывной интеграции и доставки кода, проводил обзор и оценку кода, а также подготовил и прочитал полугодовой обучающий курс «Микросервисные масштабируемые веб-сайты» для команды.
Ранее я принимал участие в проектах Роскосмоса, в том числе в разработке ПО на языке C++ для инфракрасного датчика горизонта с использованием платформы Arduino для сверхмалого космического аппарата НГУ «Норби», успешный запуск которого состоялся в 2020 году.
У меня есть диплом бакалавра НГУ в области физики пучков заряженных частиц и физики ускорителей. Я прошёл курсы повышения квалификации по разработке и эксплуатации ПО на Python и C++, алгоритмам и структурам данных, системному администрированию и обеспечению надёжности информационных систем от «Образовательных технологий Яндекса», а также основы искусственного интеллекта и машинного обучения от НГУ.
Мои технические навыки включают: отличное владение языками программирования Python и C++, разнообразными фреймворками; работу с асинхронным и параллельным кодом; проектирование ПО, веб-приложений и микросервисов; создание документации; работу с реляционными базами данных и NoSQL-хранилищами; управление очередями сообщений и задач; владение методологиями непрерывной интеграции и доставки кода, автоматизации процессов сборки, настройки и развёртывания ПО. Мой опыт позволяет ускорять процессы производства IT-продуктов за счёт поиска и устранения «узких» мест, автоматизировать процесс разработки и развёртывания приложений, контейнеризировать приложения и размещать их в облачных сервисах. Я использую актуальные инструменты для обеспечения качества, скорости и стабильности приложений, управляю инфраструктурой в парадигме Infrastructure as Code, сокращая время команды на развёртывание и масштабирование, а также налаживаю коммуникацию между участниками процесса разработки продукта: службой эксплуатации, разработчиками, заказчиками от бизнеса и многими другими.
Больше обо мне можно узнать здесь
Применение ИИ для разработки ПО
Сначала поговорим о теме, которая стремительно меняет ландшафт разработки программного обеспечения — о применении Искусственного Интеллекта.
Особый акцент мы сделаем на том, как эти технологии могут быть применены для разработки ПО.
Почему именно сейчас? Контекст и скорость изменений
Подготовка лекции
Готовить лекцию об ИИ в разработке — неблагодарное дело. Материал устаревает быстрее, чем успеваешь дописать слайд. То, что было актуально месяц назад, сегодня уже может считаться «устаревшим». Это прямое следствие экспоненциального прогресса в области, о котором часто говорит, например, Сэм Альтман:
Мы прошли горизонт событий; взлет начался.
Технологическая сингулярность и экспоненциальный прогресс
Концепция сингулярности — это точка, после которой технологический рост становится непредсказуемым и необратимым для нас. Со стороны кажется, что прогресс взрывной и мгновенный, но на самом деле он растянут во времени — мы просто не замечали его до определенного момента.
История развития ИИ: маховик раскручивался давно
Текущий бум — не случайность. Маховик начал раскручиваться давно:
- 2014-2015 гг.: Прорыв в области Generative Adversarial Networks (GAN), трансформеров.
- 2018-2020 гг.: Появление и scaling больших языковых моделей (LLM) — GPT-2, GPT-3.
- 2022 г.: Выход ChatGPT стал точкой взрыва популярности.
Рост популярности ChatGPT и инвестиции
ChatGPT набрал миллион пользователей за 5 дней. Для сравнения: Netflix потребовалось 3.5 года, Airbnb — 2.5 года, Instagram — 2.5 месяца. Это беспрецедентная скорость.
За этим последовали и беспрецедентные инвестиции:
- Рынок LLM-моделей растет двузначными числами.
- Проекты вроде
StarGate(предполагаемый совместный дата-центр Microsoft и OpenAI стоимостью в $100 млрд). - Прогнозы роста мирового ВВП за счет ИИ исчисляются триллионами долларов.
Зачем?
https://epoch.ai/gradient-updates/ai-and-explosive-growth-redux
ИИ и разработчик: данные и реалии
Использование ИИ разработчиками
Опросы показывают, что около 65% разработчиков уже используют чат-боты в своей работе.
Преувеличение возможностей ИИ
Существует важное исследование, которое часто упускают из виду:
- Разработчики склонны преувеличивать, насколько ИИ может помочь.
- В контролируемых экспериментах использование ИИ ухудшало время выполнения задач.
- Группа, которая не использовала ИИ, справлялась с задачами быстрее.
Вывод: ИИ — не волшебная таблетка. Это инструмент, эффективность которого зависит от навыка его использования.
2025-07-10-early-2025-ai-experienced-os-dev-study
Как это работает? Технические основы
Основы нейросетей
Упрощенно, в основе современных LLM лежит операция перемножения матриц. Модель — это граф с:
- Входным слоем (ваш промт, контекст).
- Множеством скрытых (промежуточных) слоев.
- Выходным слоем (ответ модели).
Провайдеры и модели
Существует множество провайдеров: OpenAI (GPT), Anthropic (Claude), Google (Gemini), Meta (Llama), Mistral и многие другие. У каждого — своя линейка моделей разного размера и capability.
Характеристики моделей
- Размер: Современные крупные модели имеют более триллиона параметров. Это позволяет им предсказывать не только следующее слово, но и сложные смысловые конструкции.
- Контекстное окно: Определяет объем текста (в токенах), который модель может «увидеть» за раз. Критически важно для работы с большими кодовыми базами. Размер токена зависит от языка (~1 токен = 0.75 слова на англ., ~1-2 символа на русск.).
- Размышляющие модели (Reasoning): Модели, которые учатся делать последовательные выводы, дополняя контекст своими «рассуждениями».
Подходы к работе с LLM
- Промтинг:
Zero-shot: Просто задать вопрос.One-shot: Дать пример ответа.Chain-of-thought: Попросить модель рассуждать шаг за шагом.
- Контекст-инжиниринг: Наиболее важен для разработки. Это искусство подачи модели релевантного контекста (вашего кода, документации, спецификации) для получения точного ответа. Важнее, чем идеальный промт.
Агенты
Агент — это LLM, помещенная в цикл принятия решений, с доступом к инструментам (Tools).
- Агентная система сама решает, какой инструмент вызвать, вызывает его, получает результат и передает его обратно модели.
- Именно агенты превращают LLM из «болтушки» в мощный инструмент для автоматизации разработки.
Инструментарий: Кодинг-агенты на практике
Введение в кодинг-агенты
Большинство современных кодинг-агентов — это, по сути, форки редактора VS Code с интегрированным ИИ-ассистентом. Популярные примеры: Cursor, Windsurf, Codeium, Aider.
Аналогия: как есть ОС Windows, macOS, Linux — так же есть и VS Code, Cursor, Zed. Каждый со своими фичами.
Типы помощников
- Ассистенты (Плагины): Например, GitHub Copilot, Amazon Q, CodeWhisperer. Работают внутри вашей IDE.
- Терминальные агенты:
aider,windsurf,claude-cli. Работают прямо в терминале, мощны для работы с целыми репозиториями. - Автономные агенты (Cursor): Полноценная среда разработки, «заточенная» под работу с ИИ.
Обзор возможностей
- Автокомплит: Модель предлагает продолжение кода по ходу его написания.
- Редактирование в файле: Можно выделить блок кода и дать команду («добавь проверку ошибок здесь»).
- Чат: Окно для диалога с моделью. Можно добавлять контекст всего проекта.
- Агентный режим: Модель сама планирует и выполняет задачи, используя инструменты (написание, запуск кода, чтение ошибок).
Правила и контекст
- Правила (
rules): Можно описать архитектурные особенности проекта, код-стайл, требования. Агент будет следовать им.- Пример правила: «Все коммиты, сделанные агентом, должны иметь префикс
[AI]в сообщении».
- Пример правила: «Все коммиты, сделанные агентом, должны иметь префикс
- Ignore: Аналог
.gitignore. Позволяет защитить чувствительные данные и секреты от отправки модели.
MCP (Model Context Protocol)
- Унифицированный протокол от OpenAI для подключения любых инструментов к любым совместимым клиентам (например, Cursor).
- Позволяет агенту работать с вашей БД, API, файловой системой, системой управления задачами и т.д.
- Ключевая технология для создания мощных кастомных агентов под специфические задачи (например, для анализа видео с камер установки).
Вопросы и ответы
Q: Какая модель сейчас лучшая по соотношению цена/качество для разработки? A: Однозначного ответа нет. Claude 3.5 Sonnet показывает отличные результаты для кода. Из opensource сильна DeepSeek Coder-V2. Важно тестировать на своих задачах. Скорость и стоимость токенов — ключевые факторы.
Q: Сложно ли интегрировать это в большой legacy-проект?
A: Да, сложность интеграции напрямую зависит от размера кодовой базы и количества кастомных инструментов. MCP — лучший друг в этом случае. Терминальные агенты (aider) часто справляются с большими проектами лучше, чем GUI-ассистенты.
Q: Может ли ИИ породить нестандартное решение, как джуниор-разработчик? A: Нет, в этом его ограничение. ИИ оперирует усредненными паттернами из своих тренировочных данных. Он гениален в шаблонных задачах, но не в изобретении принципиально новых парадигм. Его сила — скорость и объем, а не креативность.
Q: Как начать использовать это эффективно в научных проектах? A: Начните с малого:
- Поручите ИИ писать шаблонный код (парсеры логов, скрипты для предобработки видео).
- Используйте его для документирования вашего кода.
- Попробуйте сгенерировать визуализацию для ваших данных.
- Постепенно внедряйте агентов для автоматизации рутины (например, запуск расчетов, сбор результатов).
Python Tutorial
Python is a great general-purpose programming language on its own, but with the help of a few popular libraries (numpy, scipy, matplotlib and holoviews) it becomes a powerful environment for scientific computing.
We expect that many of you will have some experience with Python and Numpy; for the rest of you, this section will serve as a quick crash course both on the Python programming language and on the use of Python for scientific computing.
In this tutorial, we will cover:
- Basic Python: Basic data types, Functions, Classes
- Numpy: Arrays, Array indexing, Datatypes, Array math, Broadcasting
- Matplotlib: Plotting, Subplots, Images
- IPython: Creating notebooks, Typical workflows
Basics of Python
Python is a high-level, dynamically typed multiparadigm programming language. Python code is often said to be almost like pseudocode, since it allows you to express very powerful ideas in very few lines of code while being very readable.
We recommend to read PEP 8.
Python versions and Zen of Python
There are currently supported versions of Python 3.X. Support for Python 2.7 ended in 2020. For this class all code will use Python 3.7.
You can check your Python version at the command line by running python --version.
!python --version
Python 3.7.4
import this
The Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!
Basic data types
Numbers
Integers and floats work as you would expect from other languages:
x = 3
print(x, type(x))
3 <class 'int'>
print(x + 1) # Addition;
print(x - 1) # Subtraction;
print(x * 2) # Multiplication;
print(x ** 2) # Exponentiation;
4
2
6
9
x += 1
print(x) # Prints "4"
x *= 2
print(x) # Prints "8"
4
8
y = 2.5
print(type(y)) # Prints "<type 'float'>"
print(y, y + 1, y * 2, y ** 2) # Prints "2.5 3.5 5.0 6.25"
<class 'float'>
2.5 3.5 5.0 6.25
Note that unlike many languages, Python does not have unary increment (x++) or decrement (x--) operators.
Python also has built-in types for long integers and complex numbers; you can find all of the details in the documentation.
Booleans
Python implements all of the usual operators for Boolean logic, but uses English words rather than symbols (&&, ||, etc.):
T, F = True, False
print(type(T)) # Prints "<type 'bool'>"
<class 'bool'>
Now we let's look at the operations:
print(T and F) # Logical AND;
print(T or F) # Logical OR;
print(not T) # Logical NOT;
print(T != F) # Logical XOR;
False
True
False
True
Strings
hello = 'hello' # String literals can use single quotes
world = "world" # or double quotes; it does not matter.
print(hello, len(hello))
hello 5
hw = hello + ' ' + world # String concatenation
print(hw) # prints "hello world"
hello world
hw12 = '%s %s %d' % (hello, world, 12) # sprintf style string formatting
print(hw12) # prints "hello world 12"
hello world 12
String objects have a bunch of useful methods; for example:
s = "hello"
print(s.capitalize()) # Capitalize a string; prints "Hello"
print(s.upper()) # Convert a string to uppercase; prints "HELLO"
print(s.rjust(7)) # Right-justify a string, padding with spaces; prints " hello"
print(s.center(7)) # Center a string, padding with spaces; prints " hello "
print(s.replace('l', '(ell)')) # Replace all instances of one substring with another;
# prints "he(ell)(ell)o"
print(' world '.strip()) # Strip leading and trailing whitespace; prints "world"
Hello
HELLO
hello
hello
he(ell)(ell)o
world
You can find a list of all string methods in the documentation.
Containers
Python includes several built-in container types: lists, dictionaries, sets, and tuples.
Lists
A list is the Python equivalent of an array, but is resizeable and can contain elements of different types:
xs = [3, 1, 2] # Create a list
print(xs, xs[2])
print(xs[-1]) # Negative indices count from the end of the list; prints "2"
[3, 1, 2] 2
2
xs[2] = 'foo' # Lists can contain elements of different types
print(xs)
[3, 1, 'foo']
xs.append('bar') # Add a new element to the end of the list
print(xs)
[3, 1, 'foo', 'bar']
x = xs.pop() # Remove and return the last element of the list
print(x, xs)
bar [3, 1, 'foo']
As usual, you can find all the gory details about lists in the documentation.
Slicing
In addition to accessing list elements one at a time, Python provides concise syntax to access sublists; this is known as slicing:
nums = range(5) # range is a built-in function that creates a list of integers
print(nums) # Prints "[0, 1, 2, 3, 4]"
print(nums[2:4]) # Get a slice from index 2 to 4 (exclusive); prints "[2, 3]"
print(nums[2:]) # Get a slice from index 2 to the end; prints "[2, 3, 4]"
print(nums[:2]) # Get a slice from the start to index 2 (exclusive); prints "[0, 1]"
print(nums[:]) # Get a slice of the whole list; prints ["0, 1, 2, 3, 4]"
print(nums[:-1]) # Slice indices can be negative; prints ["0, 1, 2, 3]"
range(0, 5)
range(2, 4)
range(2, 5)
range(0, 2)
range(0, 5)
range(0, 4)
Loops
You can loop over the elements of a list like this:
animals = ['cat', 'dog', 'monkey']
for animal in animals:
print(animal)
cat
dog
monkey
If you want access to the index of each element within the body of a loop, use the built-in enumerate function:
animals = ['cat', 'dog', 'monkey']
for idx, animal in enumerate(animals):
print('#%d: %s' % (idx + 1, animal))
#1: cat
#2: dog
#3: monkey
List comprehensions:
When programming, frequently we want to transform one type of data into another. As a simple example, consider the following code that computes square numbers:
nums = [0, 1, 2, 3, 4]
squares = []
for x in nums:
squares.append(x ** 2)
print(squares)
[0, 1, 4, 9, 16]
You can make this code simpler using a list comprehension:
nums = [0, 1, 2, 3, 4]
squares = [x ** 2 for x in nums]
print(squares)
[0, 1, 4, 9, 16]
List comprehensions can also contain conditions:
nums = [0, 1, 2, 3, 4]
even_squares = [x ** 2 for x in nums if x % 2 == 0]
print(even_squares)
[0, 4, 16]
Dictionaries
A dictionary stores (key, value) pairs, similar to a Map in Java or an object in Javascript. You can use it like this:
d = {'cat': 'cute', 'dog': 'furry'} # Create a new dictionary with some data
print(d['cat']) # Get an entry from a dictionary; prints "cute"
print('cat' in d) # Check if a dictionary has a given key; prints "True"
cute
True
d['fish'] = 'wet' # Set an entry in a dictionary
print(d['fish']) # Prints "wet"
wet
print(d.get('monkey', 'N/A')) # Get an element with a default; prints "N/A"
print(d.get('fish', 'N/A')) # Get an element with a default; prints "wet"
N/A
wet
del d['fish'] # Remove an element from a dictionary
print(d.get('fish', 'N/A')) # "fish" is no longer a key; prints "N/A"
N/A
You can find all you need to know about dictionaries in the documentation.
It is easy to iterate over the keys in a dictionary:
d = {'person': 2, 'cat': 4, 'spider': 8}
for animal in d:
legs = d[animal]
print('A %s has %d legs' % (animal, legs))
A person has 2 legs
A cat has 4 legs
A spider has 8 legs
Dictionary comprehensions: These are similar to list comprehensions, but allow you to easily construct dictionaries. For example:
nums = [0, 1, 2, 3, 4]
even_num_to_square = {x: x ** 2 for x in nums if x % 2 == 0}
print(even_num_to_square)
{0: 0, 2: 4, 4: 16}
Sets
A set is an unordered collection of distinct elements. As a simple example, consider the following:
animals = {'cat', 'dog'}
print('cat' in animals) # Check if an element is in a set; prints "True"
print('fish' in animals) # prints "False"
True
False
animals.add('fish') # Add an element to a set
print('fish' in animals)
print(len(animals)) # Number of elements in a set;
True
3
animals.add('cat') # Adding an element that is already in the set does nothing
print(len(animals))
animals.remove('cat') # Remove an element from a set
print(len(animals))
3
2
Loops: Iterating over a set has the same syntax as iterating over a list; however since sets are unordered, you cannot make assumptions about the order in which you visit the elements of the set:
animals = {'cat', 'dog', 'fish'}
for idx, animal in enumerate(animals):
print('#%d: %s' % (idx + 1, animal))
# Prints "#1: fish", "#2: dog", "#3: cat"
#1: fish
#2: dog
#3: cat
Set comprehensions: Like lists and dictionaries, we can easily construct sets using set comprehensions:
from math import sqrt
print({int(sqrt(x)) for x in range(30)})
{0, 1, 2, 3, 4, 5}
Tuples
A tuple is an (immutable) ordered list of values. A tuple is in many ways similar to a list; one of the most important differences is that tuples can be used as keys in dictionaries and as elements of sets, while lists cannot. Here is a trivial example:
d = {(x, x + 1): x for x in range(10)} # Create a dictionary with tuple keys
t = (5, 6) # Create a tuple
print(type(t))
print(d[t])
print(d[(1, 2)])
<class 'tuple'>
5
1
Functions
Python functions are defined using the def keyword. For example:
def sign(x: float) -> str:
'''Function sign''' # document line
if x > 0:
return 'positive'
elif x < 0:
return 'negative'
else:
return 'zero'
for x in [-1, 0, 1]:
print(sign(x))
negative
zero
positive
help(sign)
Help on function sign in module __main__:
sign(x: float) -> str
Function sign
We will often define functions to take optional keyword arguments, like this:
def hello(name: str, loud: bool=False) -> None:
'''Function hello
If loud is True,
then the name is printed in capital letters.
'''
if loud:
print('HELLO, %s' % name.upper())
else:
print('Hello, %s!' % name)
hello('Bob')
hello('Fred', loud=True)
Hello, Bob!
HELLO, FRED
help(hello)
Help on function hello in module __main__:
hello(name: str, loud: bool = False) -> None
Function hello
If loud is True,
then the name is printed in capital letters.
Classes
The syntax for defining classes in Python is straightforward:
class Greeter:
'''Class Greeter
method greet:
If loud is True,
then the name is printed in capital letters.
'''
# Constructor
def __init__(self, name):
self.name = name # Create an instance variable
# Instance method
def greet(self, loud: bool=False) ->None:
if loud:
print('HELLO, %s!' % self.name.upper())
else:
print('Hello, %s' % self.name)
g = Greeter('Fred') # Construct an instance of the Greeter class
g.greet() # Call an instance method; prints "Hello, Fred"
g.greet(loud=True) # Call an instance method; prints "HELLO, FRED!"
Hello, Fred
HELLO, FRED!
help(Greeter)
Help on class Greeter in module __main__:
class Greeter(builtins.object)
| Greeter(name)
|
| Class Greeter
|
| method greet:
| If loud is True,
| then the name is printed in capital letters.
|
| Methods defined here:
|
| __init__(self, name)
| Initialize self. See help(type(self)) for accurate signature.
|
| greet(self, loud: bool = False) -> None
| # Instance method
|
| ----------------------------------------------------------------------
| Data descriptors defined here:
|
| __dict__
| dictionary for instance variables (if defined)
|
| __weakref__
| list of weak references to the object (if defined)
Numpy
Numpy is the core library for scientific computing in Python. It provides a high-performance multidimensional array object, and tools for working with these arrays.
To use Numpy, we first need to import the numpy package:
import numpy as np
Arrays
A numpy array is a grid of values, all of the same type, and is indexed by a tuple of nonnegative integers. The number of dimensions is the rank of the array; the shape of an array is a tuple of integers giving the size of the array along each dimension.
We can initialize numpy arrays from nested Python lists, and access elements using square brackets:
a = np.array([1, 2, 3]) # Create a rank 1 array
print(type(a), a.shape, a[0], a[1], a[2])
a[0] = 5 # Change an element of the array
print(a)
<class 'numpy.ndarray'> (3,) 1 2 3
[5 2 3]
b = np.array([[1,2,3],[4,5,6]]) # Create a rank 2 array
print(b)
[[1 2 3]
[4 5 6]]
print(b.shape)
print(b[0, 0], b[0, 1], b[1, 0])
(2, 3)
1 2 4
Numpy also provides many functions to create arrays:
a = np.zeros((2,2)) # Create an array of all zeros
print(a)
[[0. 0.]
[0. 0.]]
b = np.ones((1,2)) # Create an array of all ones
print(b)
[[1. 1.]]
c = np.full((2,2), 7) # Create a constant array
print(c)
[[7 7]
[7 7]]
d = np.eye(2) # Create a 2x2 identity matrix
print(d)
[[1. 0.]
[0. 1.]]
e = np.random.random((2,2)) # Create an array filled with random values
print(e)
[[0.57584699 0.0757792 ]
[0.18793454 0.78004389]]
Array indexing
Numpy offers several ways to index into arrays.
Slicing: Similar to Python lists, numpy arrays can be sliced. Since arrays may be multidimensional, you must specify a slice for each dimension of the array:
import numpy as np
# Create the following rank 2 array with shape (3, 4)
# [[ 1 2 3 4]
# [ 5 6 7 8]
# [ 9 10 11 12]]
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
# Use slicing to pull out the subarray consisting of the first 2 rows
# and columns 1 and 2; b is the following array of shape (2, 2):
# [[2 3]
# [6 7]]
b = a[:2, 1:3]
print(b)
[[2 3]
[6 7]]
A slice of an array is a view into the same data, so modifying it will modify the original array.
print(a[0, 1])
b[0, 0] = 77 # b[0, 0] is the same piece of data as a[0, 1]
print(a[0, 1])
2
77
You can also mix integer indexing with slice indexing. However, doing so will yield an array of lower rank than the original array.
# Create the following rank 2 array with shape (3, 4)
a = np.array([[1,2,3,4], [5,6,7,8], [9,10,11,12]])
print(a)
[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
Two ways of accessing the data in the middle row of the array. Mixing integer indexing with slices yields an array of lower rank, while using only slices yields an array of the same rank as the original array:
row_r1 = a[1, :] # Rank 1 view of the second row of a
row_r2 = a[1:2, :] # Rank 2 view of the second row of a
row_r3 = a[[1], :] # Rank 2 view of the second row of a
print(row_r1, row_r1.shape)
print(row_r2, row_r2.shape)
print(row_r3, row_r3.shape)
[5 6 7 8] (4,)
[[5 6 7 8]] (1, 4)
[[5 6 7 8]] (1, 4)
# We can make the same distinction when accessing columns of an array:
col_r1 = a[:, 1]
col_r2 = a[:, 1:2]
print(col_r1, col_r1.shape)
print(col_r2, col_r2.shape)
[ 2 6 10] (3,)
[[ 2]
[ 6]
[10]] (3, 1)
Integer array indexing: When you index into numpy arrays using slicing, the resulting array view will always be a subarray of the original array. In contrast, integer array indexing allows you to construct arbitrary arrays using the data from another array. Here is an example:
a = np.array([[1,2], [3, 4], [5, 6]])
# An example of integer array indexing.
# The returned array will have shape (3,) and
print(a[[0, 1, 2], [0, 1, 0]])
# The above example of integer array indexing is equivalent to this:
print(np.array([a[0, 0], a[1, 1], a[2, 0]]))
[1 4 5]
[1 4 5]
# When using integer array indexing, you can reuse the same
# element from the source array:
print(a[[0, 0], [1, 1]])
# Equivalent to the previous integer array indexing example
print(np.array([a[0, 1], a[0, 1]]))
[2 2]
[2 2]
One useful trick with integer array indexing is selecting or mutating one element from each row of a matrix:
# Create a new array from which we will select elements
a = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
print(a)
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
# Create an array of indices
b = np.array([0, 2, 0, 1])
# Select one element from each row of a using the indices in b
print(a[np.arange(4), b]) # Prints "[ 1 6 7 11]"
[ 1 6 7 11]
# Mutate one element from each row of a using the indices in b
a[np.arange(4), b] += 10
print(a)
[[11 2 3]
[ 4 5 16]
[17 8 9]
[10 21 12]]
Boolean array indexing: Boolean array indexing lets you pick out arbitrary elements of an array. Frequently this type of indexing is used to select the elements of an array that satisfy some condition. Here is an example:
import numpy as np
a = np.array([[1,2], [3, 4], [5, 6]])
bool_idx = (a > 2) # Find the elements of a that are bigger than 2;
# this returns a numpy array of Booleans of the same
# shape as a, where each slot of bool_idx tells
# whether that element of a is > 2.
print(bool_idx)
[[False False]
[ True True]
[ True True]]
# We use boolean array indexing to construct a rank 1 array
# consisting of the elements of a corresponding to the True values
# of bool_idx
print(a[bool_idx])
# We can do all of the above in a single concise statement:
print(a[a > 2])
[3 4 5 6]
[3 4 5 6]
For brevity we have left out a lot of details about numpy array indexing; if you want to know more you should read the documentation.
Datatypes
Every numpy array is a grid of elements of the same type. Numpy provides a large set of numeric datatypes that you can use to construct arrays. Numpy tries to guess a datatype when you create an array, but functions that construct arrays usually also include an optional argument to explicitly specify the datatype. Here is an example:
x = np.array([1, 2]) # Let numpy choose the datatype
y = np.array([1.0, 2.0]) # Let numpy choose the datatype
z = np.array([1, 2], dtype=np.int64) # Force a particular datatype
print(x.dtype, y.dtype, z.dtype)
int64 float64 int64
You can read all about numpy datatypes in the documentation.
Array math
Basic mathematical functions operate elementwise on arrays, and are available both as operator overloads and as functions in the numpy module:
x = np.array([[1,2],[3,4]], dtype=np.float64)
y = np.array([[5,6],[7,8]], dtype=np.float64)
# Elementwise sum; both produce the array
print(x + y)
print(np.add(x, y))
[[ 6. 8.]
[10. 12.]]
[[ 6. 8.]
[10. 12.]]
# Elementwise difference; both produce the array
print(x - y)
print(np.subtract(x, y))
[[-4. -4.]
[-4. -4.]]
[[-4. -4.]
[-4. -4.]]
# Elementwise product; both produce the array
print(x * y)
print(np.multiply(x, y))
[[ 5. 12.]
[21. 32.]]
[[ 5. 12.]
[21. 32.]]
# Elementwise division; both produce the array
# [[ 0.2 0.33333333]
# [ 0.42857143 0.5 ]]
print(x / y)
print(np.divide(x, y))
[[0.2 0.33333333]
[0.42857143 0.5 ]]
[[0.2 0.33333333]
[0.42857143 0.5 ]]
# Elementwise square root; produces the array
# [[ 1. 1.41421356]
# [ 1.73205081 2. ]]
print(np.sqrt(x))
[[1. 1.41421356]
[1.73205081 2. ]]
Note that unlike MATLAB, * is elementwise multiplication, not matrix multiplication. We instead use the dot function to compute inner products of vectors, to multiply a vector by a matrix, and to multiply matrices. dot is available both as a function in the numpy module and as an instance method of array objects:
x = np.array([[1,2],[3,4]])
y = np.array([[5,6],[7,8]])
v = np.array([9,10])
w = np.array([11, 12])
# Inner product of vectors; both produce 219
print(v.dot(w))
print(np.dot(v, w))
219
219
# Matrix / vector product; both produce the rank 1 array [29 67]
print(x.dot(v))
print(np.dot(x, v))
[29 67]
[29 67]
# Matrix / matrix product; both produce the rank 2 array
# [[19 22]
# [43 50]]
print(x.dot(y))
print(np.dot(x, y))
[[19 22]
[43 50]]
[[19 22]
[43 50]]
Numpy provides many useful functions for performing computations on arrays; one of the most useful is sum:
x = np.array([[1,2],[3,4]])
print(np.sum(x)) # Compute sum of all elements; prints "10"
print(np.sum(x, axis=0)) # Compute sum of each column; prints "[4 6]"
print(np.sum(x, axis=1)) # Compute sum of each row; prints "[3 7]"
10
[4 6]
[3 7]
You can find the full list of mathematical functions provided by numpy in the documentation.
Apart from computing mathematical functions using arrays, we frequently need to reshape or otherwise manipulate data in arrays. The simplest example of this type of operation is transposing a matrix; to transpose a matrix, simply use the T attribute of an array object:
print(x)
print(x.T)
[[1 2]
[3 4]]
[[1 3]
[2 4]]
v = np.array([[1,2,3]])
print(v)
print(v.T)
[[1 2 3]]
[[1]
[2]
[3]]
Broadcasting
Broadcasting is a powerful mechanism that allows numpy to work with arrays of different shapes when performing arithmetic operations. Frequently we have a smaller array and a larger array, and we want to use the smaller array multiple times to perform some operation on the larger array.
For example, suppose that we want to add a constant vector to each row of a matrix. We could do it like this:
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = np.empty_like(x) # Create an empty matrix with the same shape as x
# Add the vector v to each row of the matrix x with an explicit loop
for i in range(4):
y[i, :] = x[i, :] + v
print(y)
[[ 2 2 4]
[ 5 5 7]
[ 8 8 10]
[11 11 13]]
This works; however when the matrix x is very large, computing an explicit loop in Python could be slow. Note that adding the vector v to each row of the matrix x is equivalent to forming a matrix vv by stacking multiple copies of v vertically, then performing elementwise summation of x and vv. We could implement this approach like this:
vv = np.tile(v, (4, 1)) # Stack 4 copies of v on top of each other
print(vv) # Prints "[[1 0 1]
# [1 0 1]
# [1 0 1]
# [1 0 1]]"
[[1 0 1]
[1 0 1]
[1 0 1]
[1 0 1]]
y = x + vv # Add x and vv elementwise
print(y)
[[ 2 2 4]
[ 5 5 7]
[ 8 8 10]
[11 11 13]]
Numpy broadcasting allows us to perform this computation without actually creating multiple copies of v. Consider this version, using broadcasting:
# We will add the vector v to each row of the matrix x,
# storing the result in the matrix y
x = np.array([[1,2,3], [4,5,6], [7,8,9], [10, 11, 12]])
v = np.array([1, 0, 1])
y = x + v # Add v to each row of x using broadcasting
print(y)
[[ 2 2 4]
[ 5 5 7]
[ 8 8 10]
[11 11 13]]
The line y = x + v works even though x has shape (4, 3) and v has shape (3,) due to broadcasting; this line works as if v actually had shape (4, 3), where each row was a copy of v, and the sum was performed elementwise.
Broadcasting two arrays together follows these rules:
- If the arrays do not have the same rank, prepend the shape of the lower rank array with 1s until both shapes have the same length.
- The two arrays are said to be compatible in a dimension if they have the same size in the dimension, or if one of the arrays has size 1 in that dimension.
- The arrays can be broadcast together if they are compatible in all dimensions.
- After broadcasting, each array behaves as if it had shape equal to the elementwise maximum of shapes of the two input arrays.
- In any dimension where one array had size 1 and the other array had size greater than 1, the first array behaves as if it were copied along that dimension
If this explanation does not make sense, try reading the explanation from the documentation.
Functions that support broadcasting are known as universal functions. You can find the list of all universal functions in the documentation.
Here are some applications of broadcasting:
# Compute outer product of vectors
v = np.array([1,2,3]) # v has shape (3,)
w = np.array([4,5]) # w has shape (2,)
# To compute an outer product, we first reshape v to be a column
# vector of shape (3, 1); we can then broadcast it against w to yield
# an output of shape (3, 2), which is the outer product of v and w:
print(np.reshape(v, (3, 1)) * w)
[[ 4 5]
[ 8 10]
[12 15]]
# Add a vector to each row of a matrix
x = np.array([[1,2,3], [4,5,6]])
# x has shape (2, 3) and v has shape (3,) so they broadcast to (2, 3),
# giving the following matrix:
print(x + v)
[[2 4 6]
[5 7 9]]
# Add a vector to each column of a matrix
# x has shape (2, 3) and w has shape (2,).
# If we transpose x then it has shape (3, 2) and can be broadcast
# against w to yield a result of shape (3, 2); transposing this result
# yields the final result of shape (2, 3) which is the matrix x with
# the vector w added to each column. Gives the following matrix:
print((x.T + w).T)
[[ 5 6 7]
[ 9 10 11]]
# Another solution is to reshape w to be a row vector of shape (2, 1);
# we can then broadcast it directly against x to produce the same
# output.
print(x + np.reshape(w, (2, 1)))
[[ 5 6 7]
[ 9 10 11]]
# Multiply a matrix by a constant:
# x has shape (2, 3). Numpy treats scalars as arrays of shape ();
# these can be broadcast together to shape (2, 3), producing the
# following array:
print(x * 2)
[[ 2 4 6]
[ 8 10 12]]
Broadcasting typically makes your code more concise and faster, so you should strive to use it where possible.
This brief overview has touched on many of the important things that you need to know about numpy, but is far from complete. Check out the numpy reference to find out much more about numpy.
Scipy
To be continued...
Matplotlib
Matplotlib is a plotting library. In this section give a brief introduction to the matplotlib.pyplot module, which provides a plotting system similar to that of MATLAB.
import matplotlib.pyplot as plt
By running this special iPython command, we will be displaying plots inline:
%matplotlib inline
Plotting
The most important function in matplotlib is plot, which allows you to plot 2D data. Here is a simple example:
# Compute the x and y coordinates for points on a sine curve
x = np.arange(0, 3 * np.pi, 0.1)
y = np.sin(x)
# Plot the points using matplotlib
plt.plot(x, y)
[<matplotlib.lines.Line2D at 0x1142b94d0>]
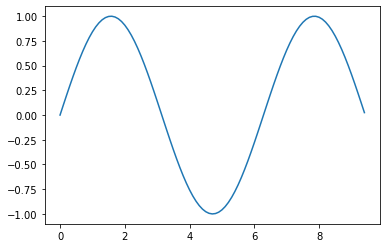
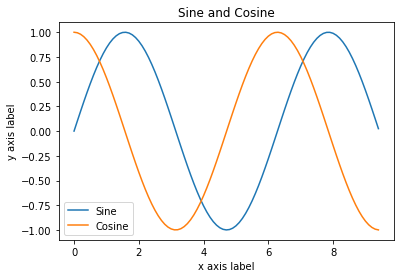
With just a little bit of extra work we can easily plot multiple lines at once, and add a title, legend, and axis labels:
y_sin = np.sin(x)
y_cos = np.cos(x)
# Plot the points using matplotlib
plt.plot(x, y_sin)
plt.plot(x, y_cos)
plt.xlabel('x axis label')
plt.ylabel('y axis label')
plt.title('Sine and Cosine')
plt.legend(['Sine', 'Cosine'])
<matplotlib.legend.Legend at 0x114390a50>
Subplots
You can plot different things in the same figure using the subplot function. Here is an example:
# Compute the x and y coordinates for points on sine and cosine curves
x = np.arange(0, 3 * np.pi, 0.1)
y_sin = np.sin(x)
y_cos = np.cos(x)
# Set up a subplot grid that has height 2 and width 1,
# and set the first such subplot as active.
plt.subplot(2, 1, 1)
# Make the first plot
plt.plot(x, y_sin)
plt.title('Sine')
# Set the second subplot as active, and make the second plot.
plt.subplot(2, 1, 2)
plt.plot(x, y_cos)
plt.title('Cosine')
# Show the figure.
plt.show()
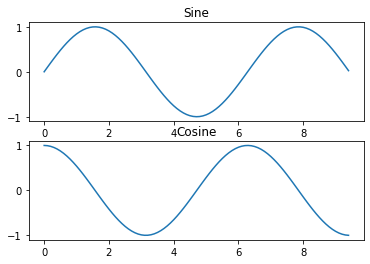
You can read much more about the subplot function in the documentation.
Holoviews
To be continued...
General requirements for Python code
- Strict compliance with PEP8.
- The length of the string is 79 characters.
- The imports are properly sorted, there are no unused imports.
- The margins are 4 spaces.
- Hyphenation with correct indentation.
- Backslashes are not used for transfers.
- Consistency (the same quotes, the same methods of solving the same problems, and so on).
- Lack of commented code and standard comments (# Create your views here. etc.).
- Comments on functions are formatted as Docstrings, in accordance with the Docstring Conventions: Begin with a capital letter, end with a period, and contain a description of what the function does.
- The comments to the code are concise and informative.
- Long pieces of code are logically separated by blank lines like paragraphs in a text.
- There are no unnecessary operations.
- There are no extra else where they are not needed (if a return/raise occurs in the if); Guard Block is used
- There are no unnecessary files in the repository: no pycache , .vscode and other things.
- The executable code in .py files must be closed with the if name == ‘main’ construction.
- For immutable sequences of data, tuples rather than lists are preferable.
- In f-strings, only variable substitution is used and there are no logical or arithmetic operations, function calls, or similar dynamics.
- Variables are named according to their meaning, in English, there are no single-letter names and transliteration. The variable name should not contain its type. If necessary, type annotations are used.
Полезные ссылки Git
- Введение в основы Git
- Создание алиасов команд
- Как просматривать историю изменений
- Один из подходов к созданию веток
- git rebase для начинающих
Полезные ссылки Docker
- Docker
- Сканеры уязвимостей контейнеров
- Docker CLI
- Виртуализация и контейнеризация
- Проникновение в Docker с примерами
- Оптимизация образов Docker
- Документация на docker network
- Docker: гибкая сеть без NAT на все случаи жизни
- Docker Compose
- Docker Compose CLI
Этот материал посвящён фундаментальным темам операционной системы Linux: процессу загрузки и организации файловых систем, инструментам консоли и внутреннему устройству. Понимание этих процессов необходимо для администрирования систем и решения возникающих проблем.
Загрузка
1. BIOS (Basic Input/Output System)
BIOS — это микропрограмма, хранящаяся на чипе материнской платы (во FLASH-памяти). При включении питания процессор выполняет первую инструкцию по адресу 0xFFFFFFF0 (так называемый reset vector), который указывает на код BIOS.
Основные функции BIOS:
- POST (Power-On Self-Test): Проверка целостности самой микропрограммы, инициализация критически важного оборудования (процессор, память, чипсет), запуск встроенного ПО других устройств (видеокарта, сетевая карта).
- Сигналы POST: Если на этапе самотестирования возникает ошибка, BIOS подаёт сигналы через системный динамик (например, 1 короткий — успех, длинные и короткие комбинации — различные ошибки).
2. Загрузчик (Bootloader)
Задача загрузчика — найти, загрузить в оперативную память и передать управление ядру операционной системы.
Схемы загрузки
-
BIOS + MBR (Master Boot Record):
- MBR — это первые 512 байт на диске. Содержит:
- Bootstrap Code (446 байт) — первичный код загрузчика.
- Partition Table (64 байта) — таблица разделов (до 4 первичных).
- Signature (2 байта) — сигнатура
55 AA.
- Ограничение MBR: работа с дисками до 2 ТБ.
- Процесс: BIOS загружает MBR, код из MBR находит активный раздел и загружает следующий этап загрузчика (например, GRUB2), который уже находится в этом разделе.
- MBR — это первые 512 байт на диске. Содержит:
-
UEFI + GPT (GUID Partition Table):
- UEFI — современный стандарт, пришедший на смену BIOS. Умеет читать файловые системы (например, FAT32) и поддерживает безопасную загрузку (Secure Boot).
- GPT — современная схема разделов, не имеющая ограничений MBR.
- Процесс: UEFI напрямую обращается к специальному FAT32-разделу (EFI System Partition), где хранятся файлы загрузчиков с расширением
.efi(например,grubx64.efi). Загрузочные записи хранятся в NVRAM.
Полезные команды:
- Просмотр UEFI-записей:
efibootmgr -v - Просмотр разделов:
fdisk -l
GRUB2 (Grand Unified Bootloader 2)
Самый распространённый загрузчик в Linux.
- Позволяет выбирать ядро или ОС для загрузки.
- Загружает необходимые модули для поддержки оборудования и файловых систем.
- Основной конфигурационный файл:
/boot/grub/grub.cfg(генерируется автоматически).
3. Ядро (Kernel)
Ядро Linux — это сжатый исполняемый файл (обычно vmlinuz-<версия> в каталоге /boot).
- GRUB загружает ядро в оперативную память.
- Ядро распаковывается.
- Ядро запускается с параметрами командной строки (можно посмотреть в
/proc/cmdline). - Ядро монтирует в памяти начальную RAM-диск (initramfs).
Initramfs (Initial RAM File System)
Это временная корневая файловая система в памяти.
- Содержит необходимые на раннем этапе загрузки драйверы, модули ядра, микрокод и скрипты.
- Его главная задача — смонтировать реальную корневую файловую систему (
/), после чего управление передаётся процессуinit.
4. Init и systemd
Процесс с PID 1 (init или systemd) является родителем для всех остальных процессов в системе.
Его основные задачи:
- Управление порядком запуска служб (демонов).
- Монтирование файловых систем (согласно
/etc/fstab). - Управление всеми запущенными процессами.
systemd — современная и самая распространённая реализация init.
- Использует концепцию юнитов (units) (сервисы, монтирования, сокеты и т.д.).
- Позволяет просматривать зависимости:
systemctl list-dependencies default.target - Имеет множество утилит для управления системой (
systemctl,journalctlи др.).
Файловые системы
1. Немного о дисках
Жёсткий диск состоит из пластин, разделённых на дорожки и секторы (обычно по 512 байт или 4 КБ). Файловая система располагается внутри раздела диска, который описывается в таблице разделов (MBR или GPT).
2. Задачи файловой системы
ФС решает несколько ключевых задач:
- Индексация и поиск данных (через структуры вроде inode).
- Управление свободным пространством.
- Контроль доступа (права, ACL).
- Оптимизация производительности (кеширование, дефрагментация*).
- Надёжность (журналирование).
*Дефрагментация менее критична для современных ФС (ext4, XFS, btrfs) и SSD.
3. Виды файловых систем
Доступ к разным ФС в Linux обеспечивается единым интерфейсом — VFS (Virtual File System).
FAT (File Allocation Table)
- Плюсы: Простая, поддерживается всеми ОС.
- Минусы: Нет журналирования, ограничения на размер файла и раздела (FAT32: файл до 4 ГБ, раздел до 32 ГБ).
- Расчёт размера: FAT12: 2^12 * размер_блока.
ext4 (Fourth Extended Filesystem)
- Стандарт для Ubuntu, Debian и многих других дистрибутивов.
- Журналируемая — повышает надёжность, записывая метаданные операций в специальный журнал перед их выполнением.
- Использует экстенты (extents) для более эффективного хранения больших файлов (вместо прямых/косвенных блоков).
- Иноды (inodes) хранят метаданные о файле (права, владелец, указатели на данные). Их количество ограничено и задаётся при создании ФС.
XFS
- Высокопроизводительная ФС, хорошо подходит для работы с большими файлами.
- Использует B+-tree для индексации.
- Отложенная аллокация — улучшает производительность.
- Динамическое создание inodes.
- Стандарт для Red Hat Enterprise Linux.
btrfs (B-Tree File System)
- Современная ФС с продвинутыми функциями.
- Copy-on-Write (CoW): При изменении файла данные записываются в новое место, а не перезаписываются старые. Это позволяет эффективно создавать снапшоты (snapshots).
- Встроенная поддержка RAID и LVM-подобных функций.
- Субаллокация — эффективная работа с маленькими файлами.
- Поддержка TRIM для SSD.
- Стандарт для openSUSE.
4. Конфигурирование файловой системы
- Кеширование: Ядро использует Page Cache (для данных) и Dirty Cache (для изменённых, но не записанных данных) для ускорения работы.
- I/O планировщики: Определяют порядок обработки запросов к диску. Доступны через
/sys/block/<device>/queue/scheduler.cfq/bfq— «честное» распределение.deadline— учитывает сроки выполнения запросов.noop— простой FIFO (часто лучше для SSD).
Утилиты для работы с ФС:
mkfs,mke2fs— создание ФС.tune2fs— изменение параметров ФС ext*.debugfs— отладка ФС ext*.fsck— проверка и восстановление ФС.
5. Монтирование
Процесс подключения раздела диска к определённой точке в дереве каталогов (/mnt, /home и т.д.).
- Команды:
mount,umount. - /etc/fstab — файл статической информации о файловых системах для автоматического монтирования при загрузке.
# Пример строки в /etc/fstab UUID=ed465c6e-949a-41c6-8e8b-c8da348a3577 / ext4 defaults 0 1 - Параметры монтирования:
rw/ro(чтение/запись),noatime(не обновлять время доступа для производительности),acl(поддержка списков контроля доступа) и др. - systemd.mount — альтернатива
fstabчерез юниты systemd.
6. RAID (Redundant Array of Independent Disks)
Технология объединения нескольких дисков в массив для повышения надёжности и/или производительности.
| Уровень | Принцип | Надёжность | Производительность | Ёмкость |
|---|---|---|---|---|
| RAID 0 | Striping (чередование) | Низкая | Высокая (чт/зап) | N |
| RAID 1 | Mirroring (зеркалирование) | Высокая | Высокая (чт) | N/2 |
| RAID 5 | Четность | Средняя | Высокая (чт) | N-1 |
| RAID 6 | Двойная четность | Высокая | Высокая (чт) | N-2 |
| RAID 10 | Зеркалирование + чередование | Высокая | Высокая (чт/зап) | N/2 |
Создание программного RAID в Linux:
Используется утилита mdadm.
# Пример создания RAID 1
mdadm --create /dev/md0 --level=1 --raid-devices=2 /dev/sdb /dev/sdc
mkfs.ext4 /dev/md0
mount /dev/md0 /mnt/raid
# Сохранение конфигурации
mdadm --detail --scan >> /etc/mdadm/mdadm.conf
7. LVM (Logical Volume Manager)
Система управления дисковым пространством, которая абстрагируется от физических дисков.
Преимущества LVM:
- Гибкое управление размерами: Легко увеличивать, уменьшать логические тома.
- Снапшоты: Возможность создания моментальных снимков томов.
- Объединение дисков: Создание томов, размер которых превышает один физический диск.
Основные понятия:
- Physical Volume (PV): Физический диск или раздел.
- Volume Group (VG): Группа физических томов.
- Logical Volume (LV): Логический том, создаваемый из пространства VG.
Основные команды:
- pvcreate /dev/sdX — создать физический том.
- vgcreate my_vg /dev/sdX1 /dev/sdY1 — создать группу томов.
- lvcreate -n my_vol -L 10G my_vg — создать логический том размером 10 ГБ.
- mkfs.ext4 /dev/my_vg/my_vol — создать ФС на томе.
Заключение
Понимание процесса загрузки и принципов работы файловых систем — ключевой навык для системного администратора Linux. Эти знания позволяют эффективно управлять системой, настраивать её под конкретные задачи, устранять неполадки и обеспечивать надёжность хранения данных.
Инструменты Linux
Лекция посвящена основным инструментам для эффективной работы в Linux-терминале. Мы рассмотрим всё: от настройки окружения до продвинутых методов диагностики проблем.
Часть 1: Подготовка и окружение
Слепая печать
Первый и самый важный навык — умение печатать, не глядя на клавиатуру.
- Преимущества: Увеличение скорости, меньше ошибок, полный контроль над терминалом.
- Сложности: Первые месяцы будут тяжелыми, но результат того стоит.
Инструменты для тренировки:
GNU Typist(gtypist) — консольный тренажер. Устанавливается черезapt-get install gtypistилиbrew install gtypist.monkeytype— современный онлайн-тренажер.www.keybr.com— еще один популярный онлайн-тренажер.
Эмулятор терминала
Стандартные терминалы часто бедны на функции. Хороший терминал должен иметь:
- Вкладки (табы).
- Разделение окна (split panels).
- Копирование в буфер обмена просто при выделении текста.
- Поддержка кликабельных ссылок.
- Система плагинов для расширения функционала.
- Прочие "рюшечки" (темы, прозрачность и т.д.).
Рекомендуемые терминалы:
- macOS:
iTerm2 - Linux:
Terminator,Kitty,Konsole - Windows 10/11:
Windows Terminal - Windows (условно-бесплатный):
MobaXterm(также включает SSH-клиент, X-сервер и сетевые инструменты).
Моноширинные шрифты
Для удобства чтения кода в терминале необходимы качественные моноширинные шрифты.
- Source Code Pro (Adobe)
- Inconsolata (Google)
- Anonymous Pro
Ссылки для скачивания приведены в презентации.
Командные оболочки (Shell)
Это интерпретатор команд, с которым вы взаимодействуете в терминале.
- bash (Bourne-Again SHell): Универсальный стандарт. Лучший выбор для разнородной инфраструктуры.
- zsh (Z Shell): Обладает расширенными возможностями и богатой экосистемой плагинов. Идеален для локальной разработки и контролируемой инфраструктуры. Фреймворк
Oh My Zshделает настройку zsh простой и приятной. - fish (Friendly Interactive SHell): Современный shell с удобством "из коробки". Выбирается по тем же причинам, что и zsh.
Часть 2: Основы командной строки
Структура команд
syscall exec— ищет исполняемый файл по путям, указанным в переменной окружения$PATH.which <команда>илиtype <команда>— показывают полный путь к исполняемому файлу команды. Флаг-aпокажет все возможные пути в$PATH.- Флаги команд не стандартизированы, но есть соглашения:
-v/--version— показать версию.-h/--help— показать справку.-y/-f— пропустить подтверждение (yes/force).
Справка man
Основной источник информации — команда man (manual).
- Пейджер: По умолчанию для просмотра используется
less. Можно изменить переменной окружения$MANPAGER(например,MANPAGER=cat). - Основные клавиши в
less:h— помощь.PgUp,PgDown,↓,↑— навигация./KEYWORD— поиск.N,n— переход к следующему/предыдущему совпадению.g— в начало документа.G— в конец документа.
man <раздел> <команда>— например,man 1 bash(справка по bash из раздела "пользовательские команды").man -P 'less +/KEYWORD' bash— открыть man с поиском по ключевому слову.
Управление процессами
Ctrl + C— послать сигналSIGINT(завершение процесса).Ctrl + \— послать сигналSIGQUIT(завершение с дампом памяти).Ctrl + Z— послать сигналSIGTSTP(приостановка процесса).fg— вернуть приостановленный процесс на передний план.bg— запустить приостановленный процесс в фоновом режиме.stty -a— посмотреть и перенастроить настройки терминала.
Управление вводом/выводом (I/O Redirection)
- Потоки данных:
stdin(0) — стандартный вход.stdout(1) — стандартный выход.stderr(2) — стандартный вывод ошибок.
- Перенаправление:
команда > файл— записатьstdoutв файл (перезаписать).команда >> файл— дописатьstdoutв конец файла.команда 2> файл— записатьstderrв файл.команда &> файл— записатьstdoutиstderrв файл.команда 2>&1— перенаправитьstderrвstdout.команда | другая_команда— передатьstdoutпервой команды наstdinвторой.
- Специальные файлы:
/dev/null— "черная дыра"./dev/zero— источник нулей./dev/urandom— источник псевдослучайных чисел.
Полезные помощники
- Автодополнение (completion): Клавиша
TAB— ваш лучший друг.- Одно нажатие — дополнить команду/файл.
- Двойное нажатие — показать все возможные варианты.
- История команд (
~/.bash_history,~/.zsh_history):Ctrl + R— реверсивный поиск по истории.history | grep <ключевое_слово>— поиск по истории.sudo !!— выполнить предыдущую команду сsudo.!$— подставить последний аргумент предыдущей команды.
Ветвления, циклы и подоболочки (Subshell)
;— разделитель команд (выполняются последовательно).- Циклы и условия:
while true; do ...; done for i in $(seq 1 10); do echo $i; done if [ $(wc -l file.txt) -gt 3 ]; then ...; fi read— встроенная команда для чтения ввода в переменные.- Подоболочка (Command Substitution):
$(команда)или`команда`— вывод команды подставляется в строку.
[— это бинарник, а не синтаксис shell. Подробнее:man [илиman test.
Часть 3: Полезные команды и утилиты
Find и многопоточность
find— мощный поиск файлов и директорий.- Пример:
find /etc -type f -name "nginx*"
- Пример:
xargs— передает результаты изstdinв аргументы другой команды.-P <N>— запуск до N процессов параллельно.-n1— передавать по одному аргументу за раз.- Пример:
find ... | xargs -P10 -n1 md5sum
GNU parallel— более мощная альтернативаxargsдля параллельного выполнения.
Управление сессиями: screen и tmux
Позволяют запускать процессы, которые продолжают работать после разрыва соединения.
-
screen:screen— создать новую сессию.Ctrl + A, D— отключиться от сессии (detach).screen -ls— список сессий.screen -r <session>— подключиться к сессии.
-
tmux(рекомендуется):tmux— создать сессию.Ctrl + B, D— отключиться.tmux ls— список сессий.tmux a -t <session>— подключиться.- Интеграция с
iTerm2:tmux -CC.
-
watch -d -n1 "команда"— выполняет команду раз в секунду и подсвечивает различия.
Редактирование текста
- Vim:
- Мощный, вездесущий, имеет крутую кривую обучения.
vimtutor— встроенный интерактивный учебник. Пройдите его!- Основы:
i— вход в режим вставки,ESC— возврат в нормальный режим,:wq— сохранить и выйти,:q!— выйти без сохранения. vimdiff file1 file2— сравнение файлов.
- Emacs: Другой мощный редактор. "Если вы знаете, что это, скорее всего, вам не нужна эта лекция".
- Система контроля версий Git: Обязательный инструмент для любой современной IT-профессии.
Потоковая обработка текста
Мощные утилиты для фильтрации и преобразования текстовых потоков. Не используйте их для построения продакшен-процессов!
grep— фильтрация строк по регулярному выражению.awk— целый язык для обработки текста, основанный на колонках.sed— потоковый текстовый редактор (замена, удаление строк и т.д.).cut— извлечение конкретных колонок.head/tail— вывод начала/конца файла.tr— замена или удаление символов.wc— подсчет строк, слов, символов.sort— сортировка строк.uniq— фильтрация повторяющихся строк.
Тренажеры: grepexercises, sedexercises, awkexercises (устанавливаются через pip).
Практика: The Command Line Murders — текстовый квест в терминале для отработки навыков. (https://github.com/veltman/clmystery)
Часть 4: Диагностика и поиск проблем
Методология и ресурсы
- Брендан Грегг (Brendan Gregg) — гуру производительности.
- Его сайт — кладезь информации: https://www.brendangregg.com/linuxperf.html
- Книга "Systems Performance: Enterprise and the Cloud" — must-read для углубленного изучения.
На его сайте можно найти бесценные диаграммы выбора инструментов:
- Linux Observability Tools
- Linux Static Performance Tools
- Linux Benchmarking Tools
- Linux Tuning Tools
Мини-топ полезных утилит
- Мониторинг процессов и системы:
top/htop— интерактивный просмотр процессов.atop— расширенный мониторинг, может записывать данные в файл.pidof— найти PID по имени процесса.ps fauxw | less— детальный список процессов.
- Диски и файловая система:
df -h/df -ih— место на дисках и inodes.du -sh /path/*— размер директорий.iostat -x 1— статистика ввода-вывода.
- Сеть:
ss -s/netstat -ntlp— статистика сокетов и открытые порты.ping/traceroute/mtr— диагностика сетевой связности.tcpdump— "сниффер" сетевых пакетов.ethtool eth0— настройки и статистика сетевого интерфейса.
- Прочее:
lsof -i:포트/lsof -p $PID— список открытых файлов сокетов процессом.strace -fp $PID/strace $cmd— трассировка системных вызовов.dmesg -T— просмотр логов ядра.perf top -F99— профилирование системы в реальном времени.curl— мастер на все руки для работы с HTTP/сетью.
Заключение
Освоение терминала и его инструментов — это путь к настоящей эффективности в Linux. Начинайте с основ: печать, терминал, справка man. Постепенно внедряйте в свою практику более сложные инструменты, такие как vim, tmux, grep, awk и sed. Не бойтесь экспериментировать и использовать ресурсы, подобные сайту Брендана Грегга, для углубления знаний.
Удачи в освоении мощного мира Linux-инструментов!
Установка Arch Linux
Введение
В этом руководстве мы рассмотрим процесс установки Arch Linux на виртуальной машине в VirtualBox. Сначала мы настроим виртуальную машину для использования Legacy BIOS, установим Arch Linux вручную, а затем переключимся на UEFI и настроим загрузчик для работы с UEFI.
Создание виртуальной машины
- Откройте VirtualBox и создайте новую виртуальную машину.
- Введите имя виртуальной машины и выберите тип операционной системы Linux и версию Arch Linux (64-bit).
- Выделите необходимое количество оперативной памяти (рекомендуется не менее 2 ГБ).
- Создайте новый виртуальный жесткий диск и выберите формат VDI.
- Выделите место на диске (рекомендуется не менее 20 ГБ).
- В настройках виртуальной машины выберите Legacy BIOS (или SeaBIOS).
- Выберите ISO образ Arch Linux.
Установка Arch Linux с использованием Legacy BIOS
-
Запустите виртуальную машину и загрузитесь с ISO образа Arch Linux.
-
Используйте
cfdiskдля разметки диска (/dev/sda). Создайте следующие разделы:/dev/sda1: 1G для EFI System Partition (ESP)/dev/sda2: остальное пространство для корневой файловой системы
-
Создайте файловую систему на ESP разделе:
mkfs.fat -F32 /dev/sda1 -
Создайте файловую систему на корневом разделе:
mkfs.ext4 /dev/sda2 -
Смонтируйте корневую файловую систему:
mount /dev/sda2 /mnt -
Создайте и смонтируйте ESP:
mkdir /mnt/boot mount /dev/sda1 /mnt/boot -
Установите базовую систему:
pacstrap /mnt base linux linux-firmware -
Сгенерируйте файл fstab:
genfstab -U /mnt >> /mnt/etc/fstab -
Перейдите в новую систему:
arch-chroot /mnt -
Установите загрузчик GRUB:
pacman -S grub grub-install --target=i386-pc /dev/sda grub-mkconfig -o /boot/grub/grub.cfg -
Установите пароль root:
passwd -
Выйдите из chroot окружения и размонтируйте файловые системы:
exit umount -R /mnt reboot
Установка Arch Linux на RAID1
-
Запустите установочный образ Arch Linux.
-
Подготовьте диски:
cfdisk /dev/sda cfdisk /dev/sdbСоздайте разделы на обоих дисках (например,
/dev/sda1и/dev/sdb1). -
Создайте RAID1 массив:
mdadm --create --verbose /dev/md0 --level=1 --raid-devices=2 /dev/sda1 /dev/sdb1 -
Форматируйте RAID массив:
mkfs.ext4 /dev/md0 -
Смонтируйте файловую систему:
mount /dev/md0 /mnt -
Установите базовую систему:
pacstrap /mnt base linux linux-firmware mdadm -
Сгенерируйте fstab:
genfstab -U /mnt >> /mnt/etc/fstab -
Выполните chroot в новую систему:
arch-chroot /mnt -
Настройте mdadm:
mdadm --detail --scan >> /etc/mdadm.conf -
Настройте mkinitcpio:
Откройте
/etc/mkinitcpio.confи добавьтеmdadm_udevв HOOKS перед filesystems:HOOKS=(base udev autodetect modconf block mdadm_udev filesystems keyboard fsck) -
Пересоберите начальный RAM диск:
mkinitcpio -P -
Установите GRUB:
pacman -S grub -
Установите GRUB на оба диска:
grub-install --target=i386-pc /dev/sda grub-install --target=i386-pc /dev/sdb -
Создайте конфигурацию GRUB:
grub-mkconfig -o /boot/grub/grub.cfg -
Перезагрузите систему:
exit umount -R /mnt reboot
После завершения установки, проверьте, что система загружается с любого из дисков, отключая поочередно каждый из них.
Переключение на UEFI и настройка загрузчика
-
Остановите виртуальную машину.
-
В настройках виртуальной машины измените BIOS на UEFI.
-
Запустите виртуальную машину и загрузитесь с ISO образа Arch Linux.
-
Смонтируйте корневую файловую систему и ESP:
mount /dev/sda2 /mnt mount /dev/sda1 /mnt/boot arch-chroot /mnt -
Установите необходимые пакеты для загрузки с UEFI:
pacman -S grub efibootmgr dosfstools os-prober mtools -
Установите загрузчик GRUB с поддержкой UEFI:
grub-install --target=x86_64-efi --efi-directory=/boot --bootloader-id=GRUB grub-mkconfig -o /boot/grub/grub.cfg efibootmgr -v
Вы должны увидеть запись для GRUB в выводе команды efibootmgr -v.
Внутреннее устройство Linux
Введение
Почему важно изучать внутреннее устройство Linux
Linux доминирует в современных IT-инфраструктурах:
- 90% облачных инстансов работают на Linux
- Все суперкомпьютеры из топ-500 используют Linux
- Android (на базе Linux) - самая популярная мобильная ОС
- Встроенные системы и IoT устройства в основном на Linux
Понимание внутренних механизмов позволяет:
- Диагностировать сложные проблемы - от зависаний до утечек памяти
- Оптимизировать производительность - понимать, куда смотреть при нагрузке
- Писать эффективный код - знать стоимость системных вызовов
- Эффективно использовать облака - понимать, что происходит "под капотом"
Ключевой принцип: "Облака — это просто компьютеры в другом месте". Все те же процессы, память, сеть, но в удаленном дата-центре.
1. Зачем изучать Linux?
Практическая ценность глубоких знаний
Быстрая диагностика проблем
# Вместо случайного тыкания
strace -p <pid> # что делает процесс?
perf record -g <command> # где тратится время?
cat /proc/<pid>/status # в каком состоянии?
Пример из практики: Сервис периодически "зависал".
Анализ показал, что процесс переходил в состояние D (Uninterruptible sleep) при работе с NFS.
Решение: настройка таймаутов и retry-логики.
Эффективное программирование
Знание стоимости операций:
- Системный вызов: ~1000 циклов CPU
- Context switch: ~1000-10000 циклов
- Page fault: ~10-100 микросекунд
Оптимизация: Сведение системных вызовов к минимуму, использование буферизации.
Облачные технологии
Контейнеры, оркестрация, serverless - все построено на механизмах Linux:
- Docker → cgroups + namespaces
- Kubernetes → управление процессами в масштабе
- AWS Lambda → изоляция и быстрый запуск
2. Процессы
Детальное понимание процессов
Что такое процесс на самом деле?
Процесс - это не просто "запущенная программа", это контейнер выполнения с:
Ресурсы:
- Виртуальное адресное пространство
- Открытые файловые дескрипторы
- Учетные данные и привилегии
- Сигнальные маски и обработчики
Метаданные:
- PID, PPID, UID, GID
- Приоритеты планирования
- Состояние выполнения
- Потребление ресурсов
Структура процесса в ядре
// Упрощенная task_struct (include/linux/sched.h)
struct task_struct {
volatile long state; // состояние процесса
void *stack; // указатель на стек
struct mm_struct *mm; // память процесса
struct files_struct *files; // открытые файлы
struct signal_struct *signal; // сигналы
// ... сотни полей
};
Практическое использование:
# Анализ конкретного процесса
ls -la /proc/1234/
cat /proc/1234/maps # память процесса
cat /proc/1234/status # состояние и лимиты
ls /proc/1234/fd/ # открытые файлы
Создание процессов: fork() и exec()
Механизм Copy-on-Write (CoW)
До оптимизации:
fork()копировал всю память родителя- Очень дорогая операция для больших процессов
После CoW:
- Страницы памяти помечаются как read-only
- Реальная копия происходит только при записи
- Экономия памяти и времени
pid_t pid = fork();
if (pid == 0) {
// Дочерний процесс
// Страницы памяти разделяются до первой записи
execve("/bin/ls", args, env);
} else {
// Родительский процесс
waitpid(pid, &status, 0);
}
Потоки (Threads) vs Процессы
Архитектурные различия
| Аспект | Процесс | Поток |
|---|---|---|
| Память | Изолированная | Разделяемая |
| Файлы | Отдельные таблицы | Общая таблица |
| Стоимость создания | Высокая | Низкая |
| Изоляция | Полная | Минимальная |
Практические сценарии использования
Используем процессы когда:
- Нужна изоляция отказоустойчивости
- Работа с разными security-контекстами
- Масштабирование на несколько машин
Используем потоки когда:
- Разделение состояния (кеш, соединения)
- Низкая задержка взаимодействия
- Эффективное использование CPU кэша
Межпроцессное взаимодействие (IPC)
Сигналы - асинхронные уведомления
// Отправка сигнала
kill(pid, SIGTERM);
// Обработка сигнала
void handler(int sig) {
// Асинхронно! Осторожно с shared state
}
signal(SIGTERM, handler);
Важно: Большинство функций не являются signal-safe! Используйте только async-signal-safe функции в обработчиках.
Pipes - однонаправленная коммуникация
# Неименованные каналы
ls -la | grep ".txt" | wc -l
# Именованные каналы (FIFO)
mkfifo mypipe
echo "data" > mypipe &
cat mypipe
Особенности:
- Буферизация на уровне ядра
- Blocking I/O по умолчанию
- Размер буфера можно настраивать
Разделяемая память - максимальная производительность
// Создание shared memory
int shm_id = shmget(key, size, IPC_CREAT | 0666);
void *ptr = shmat(shm_id, NULL, 0);
// Использование
memcpy(ptr, data, data_size);
Преимущества:
- Нет копирования данных
- Минимальная задержка
- Прямой доступ к памяти
Недостатки:
- Сложная синхронизация
- Риск состояния гонки
Семафоры - координация доступа
// Бинарный семафор (мьютекс)
sem_wait(&mutex);
// Критическая секция
sem_post(&mutex);
Типы семафоров:
- Binary (0 или 1) - для взаимного исключения
- Counting - для ограничения ресурсов
Состояния процессов: полный цикл жизни
Детали каждого состояния
R (Running/Runnable):
- Процесс готов к выполнению или выполняется
- Находится в runqueue планировщика
- Может быть ограничен только доступностью CPU
S (Interruptible Sleep):
- Ожидание события (I/O, семафор, сигнал)
- Может быть прерван сигналом
- Типичное состояние для I/O bound процессов
D (Uninterruptible Sleep):
- Ожидание аппаратного I/O (диск, сеть)
- Не может быть прерван даже kill -9
- Опасное состояние - может привести к hung process
T (Stopped):
- Приостановлен сигналом (SIGSTOP, SIGTSTP)
- Может быть продолжен (SIGCONT)
- Используется дебаггерами
Z (Zombie):
- Процесс завершен, но родитель не забрал статус
- Ресурсы освобождены, осталась только запись в таблице процессов
- Лечение: завершить родительский процесс
Практический мониторинг
# Понимание состояния процессов
ps aux | awk '{print $8}' | sort | uniq -c
# Поиск проблемных процессов
# Процессы в D состоянии
ps aux | awk '$8=="D" {print $0}'
# Zombie процессы
ps aux | awk '$8=="Z" {print $0}'
3. Планировщик (Scheduler)
Эволюция планировщиков Linux
O(N) планировщик (до 2.4)
// Псевдокод старого планировщика
for (each task in system) {
calculate_goodness(task);
if (goodness > max_goodness) {
next_task = task;
max_goodness = goodness;
}
}
Проблемы: O(N) сложность, не масштабировался на многоядерные системы
O(1) планировщик (2.6.0 - 2.6.22)
- Две очереди: active и expired
- Bitmap для быстрого поиска
- Константное время планирования
Достижения: Хорошая масштабируемость, поддержка SMP
CFS (Completely Fair Scheduler) (2.6.23+)
// Основан на красно-черных деревьях
struct rb_root_cached {
struct rb_root rb_root;
struct rb_node *rb_leftmost;
};
Философия: "Справедливое" распределение CPU времени
Приоритеты и политики планирования
Real-Time политики
SCHED_FIFO (First-In-First-Out):
- Бесконечный time slice
- Вытесняется только более приоритетным RT процессом
- Опасность: может занять CPU навсегда
SCHED_RR (Round Robin):
- Фиксированный time slice (100ms по умолчанию)
- Циклическое переключение между процессами одинакового приоритета
- Более безопасен чем FIFO
Normal политики
SCHED_NORMAL/OTHER:
- Динамические приоритеты (nice значения)
- Интерактивные процессы получают "бонус"
- Фоновые процессы слегка "штрафуются"
Nice значения и приоритеты
# Установка nice значения
nice -n 10 ./long_running_task # низкий приоритет
nice -n -20 ./critical_task # высокий приоритет
# Изменение running процесса
renice -n 5 -p 1234
Диапазон: -20 (высший) до +19 (низший)
CFS: внутреннее устройство
Ключевые концепции
Virtual Runtime (vruntime):
- Время выполнения, нормализованное по приоритету
- Процессы с меньшим vruntime выполняются первыми
- Nice значения влияют на скорость накопления vruntime
Target Latency:
- Время, за которое все runnable процессы должны выполниться
- По умолчанию: 6ms для desktop, 24ms для server
Minimal Granularity:
- Минимальное время выполнения перед вытеснением
- 0.75ms для предотвращения частого переключения
Реализация на красно-черных деревьях
// Вставка процесса в дерево
struct sched_entity {
struct rb_node run_node;
u64 vruntime;
// ...
};
// Быстрый поиск процесса с минимальным vruntime
struct task_struct *pick_next_task(struct rq *rq) {
struct rb_node *left = rb_first_cached(&rq->tasks_timeline);
return rb_entry(left, struct task_struct, se.run_node);
}
Преимущества: O(log N) для вставки/удаления
Управление планировщиком на практике
CPU Affinity
# Привязка процесса к конкретным ядрам
taskset -c 0,1 ./application
# Просмотр текущей маски
taskset -p 1234
# Запуск с распределением по ядрам
numactl --cpunodebind=0,1 --membind=0,1 ./app
Сценарии использования:
- Изоляция критичных процессов
- Улучшение locality кэша
- NUMA-оптимизация
Настройка планировщика
# Просмотр параметров
cat /proc/sys/kernel/sched_min_granularity_ns
cat /proc/sys/kernel/sched_latency_ns
# Изменение параметров
echo 10000000 > /proc/sys/kernel/sched_latency_ns
Мониторинг планировщика
# Статистика переключений
cat /proc/1234/sched
# Очереди выполнения
cat /proc/sched_debug
# Профилирование
perf sched record ./application
perf sched latency
4. Прерывания
Архитектура прерываний в x86/x64
Аппаратные прерывания (IRQs)
Источники:
- Таймеры
- Сетевые карты
- Дисковые контроллеры
- USB устройства
Механизм:
// Регистрация обработчика
request_irq(IRQ_NUMBER, handler, flags, name, dev);
// Обработчик прерывания
static irqreturn_t my_handler(int irq, void *dev_id) {
// Быстрая обработка
return IRQ_HANDLED;
}
Исключения процессора
Типы:
- Faults - исправимые (page fault)
- Traps - преднамеренные (breakpoints)
- Aborts - фатальные ошибки
Обработка прерываний: Upper и Bottom Halves
Upper Half (Верхняя половина)
Требования:
- Максимально быстрое выполнение
- Минимальная работа
- Без блокирующих операций
// Типичный upper half
irqreturn_t eth_interrupt(int irq, void *dev_id) {
struct net_device *dev = dev_id;
disable_irq_nosync(dev->irq);
schedule_work(&dev->tx_work);
return IRQ_HANDLED;
}
Bottom Half (Нижняя половина)
Механизмы:
-
SoftIRQs:
- Статические в ядре (сеть, блокирующие устройства)
- Очень быстрые, но сложные в использовании
-
Tasklets:
- Динамические, atomic scheduling
- Не могут выполняться параллельно
-
Work Queues:
- Выполняются в контексте процесса
- Могут sleep и использовать блокирующие вызовы
// Work queue пример
DECLARE_WORK(my_work, my_work_function);
void my_work_function(struct work_struct *work) {
// Медленная обработка
process_packets();
enable_irq(dev->irq);
}
Практическая работа с прерываниями
Мониторинг прерываний
# Статистика прерываний
cat /proc/interrupts
# Распределение прерываний по CPU
cat /proc/irq/*/smp_affinity
# Изменение привязки прерываний
echo 2 > /proc/irq/24/smp_affinity
Оптимизация обработки
Techniques:
- Balance IRQs across CPUs
- Use MSI instead of legacy interrupts
- Tune network queue sizes
- Adjust IRQ coalescing settings
5. Системные вызовы
Механизм системных вызовов
Переключение между пространствами
Пользовательское пространство → Пространство ядра:
; x86-64 системный вызов
mov rax, 1 ; номер syscall (write)
mov rdi, 1 ; fd (stdout)
mov rsi, buffer ; буфер
mov rdx, count ; размер
syscall ; переход в ядро
Процесс переключения:
- Сохранение контекста пользователя
- Переход в режим ядра
- Валидация параметров
- Выполнение операции
- Возврат результата
- Восстановление контекста
Таблица системных вызовов
// Определение syscall (kernel/sys.c)
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
struct fd f = fdget_pos(fd);
// ... обработка
return ret;
}
Важно: Все параметры проверяются на валидность!
Безопасность системных вызовов
Проверки доступа
// Проверка указателей из userspace
if (copy_from_user(kernel_buf, user_buf, size))
return -EFAULT;
// Проверка прав доступа
if (!file_permission(file, MAY_READ))
return -EPERM;
Capabilities-based security
// Вместо проверки UID == 0
if (!capable(CAP_SYS_ADMIN))
return -EPERM;
Производительность системных вызовов
Измерение стоимости
#include <sys/time.h>
struct timeval start, end;
gettimeofday(&start, NULL);
// системный вызов
gettimeofday(&end, NULL);
long microseconds = (end.tv_sec - start.tv_sec) * 1000000
+ (end.tv_usec - start.tv_usec);
Типичные затраты:
- Простой syscall: 0.1 - 1 микросекунда
- I/O syscalls: 1 - 1000 микросекунд
- Context switch: 1 - 10 микросекунд
Оптимизация
Методы:
- Batch operations (writev вместо множества write)
- Memory mapping (mmap вместо read/write)
- Avoid unnecessary syscalls
- Use vDSO для частых вызовов (gettimeofday)
6. Память процесса
Виртуальная память: полная картина
Макет адресного пространства
0x0000000000000000 ┌─────────────────┐
│ Зарезервировано │
│ (NULL-ptr guard) │
0x0000000000400000 ├─────────────────┤
│ Text │
│ (код программы) │
0x0000000000600000 ├─────────────────┤
│ Data (init) │
│ (инициализированные)│
0x0000000000601000 ├─────────────────┤
│ BSS (uninit) │
│ (неинициализированные)│
0x0000000000800000 ├─────────────────┤
│ Heap │
│ (динамическая) │
│ ↓ │
0x00007ffff0000000 ├─────────────────┤
│ MMAP region │
│ (библиотеки, │
│ shared mem) │
0x00007ffff7a00000 ├─────────────────┤
│ Stack │
│ (автоматические) │
│ ↑ │
0x00007ffffff00000 ├─────────────────┤
│ Kernel space │
│ (недоступно) │
0xffffffffffffffff └─────────────────┘
Управление памятью на практике
Анализ памяти процесса
# Детальная информация о памяти
pmap -XX 1234
# Статистика памяти
cat /proc/1234/smaps
# Page faults
ps -o min_flt,maj_flt,cmd -p 1234
Типы page faults
Minor Fault:
- Страница в физической памяти
- Но не отображена в page tables процесса
- Быстрое разрешение
Major Fault:
- Страница не в физической памяти
- Требуется загрузка с диска
- Медленное разрешение
Проблемы с памятью и решения
Out of Memory (OOM)
Механизм OOM killer:
- Ядро обнаруживает нехватку памяти
- Вычисляет "badness score" для каждого процесса
- Выбирает и завершает процесс с максимальным score
Управление OOM:
# Настройка политики OOM
echo -1000 > /proc/1234/oom_score_adj # защитить процесс
echo 1000 > /proc/1234/oom_score_adj # первым кандидат
# Ручной вызов OOM killer
echo f > /proc/sysrq-trigger
SWAP управление
# Мониторинг swap
swapon --show
free -h
# Настройка swappiness
echo 10 > /proc/sys/vm/swappiness # меньше swap (сервер)
echo 60 > /proc/sys/vm/swappiness # больше swap (десктоп)
NUMA оптимизация
# Информация о NUMA
numactl --hardware
# Запуск с учетом NUMA
numactl --membind=0 --cpunodebind=0 ./application
# Статистика NUMA
cat /proc/1234/numa_maps
7. Изоляция
Эволюция изоляции в Linux
От chroot до контейнеров
Историческое развитие:
- 1979: chroot в UNIX
- 2000: FreeBSD Jails
- 2001: Linux-VServer
- 2004: Solaris Zones
- 2008: LXC (Linux Containers)
- 2013: Docker
- 2014: Kubernetes
Cgroups: управление ресурсами
Иерархия cgroups v2
/sys/fs/cgroup/
├── system.slice/ # системные службы
│ ├── ssh.service
│ └── docker.service
├── user.slice/ # пользовательские процессы
│ ├── user-1000.slice
│ └── user-1001.slice
├── kubepods.slice/ # Kubernetes pods
│ ├── pod1/
│ └── pod2/
└── cgroup.controllers # доступные контроллеры
Контроллеры ресурсов
CPU:
# Ограничение CPU
echo "200000 1000000" > /sys/fs/cgroup/mygroup/cpu.max
# 200ms из каждых 1000ms
# CPU shares
echo 512 > /sys/fs/cgroup/mygroup/cpu.weight
Память:
# Лимит памяти
echo 1G > /sys/fs/cgroup/mygroup/memory.max
# SWAP лимит
echo 2G > /sys/fs/cgroup/mygroup/memory.swap.max
# OOM политика
echo "oom_group" > /sys/fs/cgroup/mygroup/memory.oom.group
I/O:
# Ограничение дискового I/O
echo "8:0 rbps=1048576 wbps=1048576" > /sys/fs/cgroup/mygroup/io.max
Namespaces: изоляция представлений
Типы namespaces
| Namespace | Изолирует | Команда |
|---|---|---|
| PID | Process IDs | unshare --pid |
| Network | Network stack | unshare --net |
| Mount | Filesystem mounts | unshare --mount |
| UTS | Hostname, domain | unshare --uts |
| IPC | System V IPC | unshare --ipc |
| User | User/group IDs | unshare --user |
| Cgroup | Cgroup hierarchy | unshare --cgroup |
| Time | System time | unshare --time |
Практическое использование namespaces
Создание изолированного окружения:
# Создание namespace и запуск процесса
sudo unshare --fork --pid --mount-proc bash
# В новом namespace:
ps aux # видит только свои процессы
mount # видит только свои mount points
Docker-подобный контейнер вручную:
# Создание root filesystem
mkdir /mycontainer
debootstrap stable /mycontainer
# Запуск в изоляции
unshare --fork --pid --mount-proc --net --uts chroot /mycontainer /bin/bash
# В контейнере:
hostname mycontainer
ip link set lo up
Заключение
Понимание внутреннего устройства Linux - это не академическое знание, а практический инструмент для создания надежных, производительных и безопасных систем.
Python. Начало
… in December 1989, I was looking for a “hobby” programming project that would keep me occupied during the week around Christmas. My office … would be closed, but I had a home computer, and not much else on my hands.
Foreword for “Programming Python” (1st ed.)
Объекты, память и управляющие конструкции в Python
В этой главе мы углубимся в то, как Python работает с памятью, что такое изменяемые и неизменяемые объекты, и как эффективно использовать условные конструкции и циклы. Мы также затронем некоторые неочевидные аспекты языка, которые помогут вам писать более качественный код.
Объекты в памяти
В Python всё является объектом. Каждый объект имеет:
- Тип (например,
int,str,list), - Значение (например,
42,"hello"), - Уникальный идентификатор в памяти, который можно получить с помощью функции
id().
Пример:
s = "hello"
print(id(s)) # Выведет что-то вроде 4390213040
Ссылки, а не копирования
Когда вы присваиваете переменную другой переменной, вы создаёте ссылку на тот же объект, а не копируете его:
a = [1, 2, 3]
b = a
b.append(4)
print(a) # [1, 2, 3, 4] – изменился и a!
Сравнение: is vs ==
isпроверяет, ссылаются ли две переменные на один и тот же объект.==проверяет, равны ли значения объектов.
Пример:
x = [1, 2]
y = [1, 2]
print(x == y) # True
print(x is y) # False
Неочевидное поведение: кэширование целых чисел
Python кэширует небольшие целые числа (от -5 до 256). Поэтому:
a = 256
b = 256
print(a is b) # True
c = 257
d = 257
print(c is d) # False (вне диапазона кэширования)
💡 Золотое правило: всегда используйте
==для сравнения значений, аis— только для проверки наNone.
Изменяемые и неизменяемые объекты
Неизменяемые (immutable)
int,float,str,tuple,bytes,bool.- Нельзя изменить после создания. Любая операция создаёт новый объект.
Пример:
s = "hello"
print(id(s))
s += "!"
print(id(s)) # ID изменился – это новый объект!
Изменяемые (mutable)
list,dict,set.- Можно изменять без создания нового объекта.
Пример:
lst = [1, 2]
print(id(lst))
lst.append(3)
print(id(lst)) # ID остался прежним
Неочевидный нюанс: кортежи с изменяемыми элементами
Кортеж неизменяем, но если он содержит изменяемые объекты, их можно менять:
t = ([1, 2], [3, 4])
t[0].append(3)
print(t) # ([1, 2, 3], [3, 4]) – это допустимо!
Строки и байты
Строки (str)
- Предназначены для текста (Unicode).
- Неизменяемы.
Байты (bytes)
- "Сырые" данные (числа от 0 до 255).
- Тоже неизменяемы.
Пример преобразования:
text = "привет"
encoded = text.encode('utf-8') # str -> bytes
decoded = encoded.decode('utf-8') # bytes -> str
Условные конструкции
Базовый синтаксис
temperature = 15
if temperature > 20:
print("Наденьте футболку")
else:
print("Лучше взять куртку")
Элегантные проверки
Используйте "истинность" объектов:
name = input("Введите имя: ")
if name: # False, если строка пустая
print(f"Привет, {name}!")
else:
print("Привет, незнакомец!")
Современный match (Python 3.10+)
Аналог switch из других языков:
http_status = 404
match http_status:
case 200 | 201:
print("Успех")
case 401 | 403 | 404:
print("Ошибка клиента")
case 500 | 503:
print("Ошибка сервера")
case _:
print("Неизвестный статус")
💡 Совет: используйте
match, когда сравниваете одну переменную с несколькими значениями. Для сложных условий оставайтесь сif/elif/else.
Циклы
while
i = 1
while i < 1000:
print(i)
i *= 2
for и range
for i in range(5): # 0, 1, 2, 3, 4
print(i)
for i in range(1, 10, 2): # 1, 3, 5, 7, 9
print(i)
enumerate для получения индекса
for idx, char in enumerate("abc"):
print(f"Индекс: {idx}, Символ: {char}")
Неочевидный трюк: else в циклах
Блок else выполняется, если цикл завершился естественно (без break):
for i in range(5):
if i == 10:
break
else:
print("Цикл завершился без break")
Производительность при работе со строками
Помните задачу сборки строки по частям?
Неэффективный способ:
result = ""
for _ in range(100000):
result += "a" # Создаёт новый объект на каждой итерации!
Эффективный способ:
parts = []
for _ in range(100000):
parts.append("a")
result = "".join(parts) # Быстрое объединение
💡 Совет: для частых операций конкатенации используйте
list+join()для строк илиbytearrayдля байтов.
Сборка мусора
Python использует двухуровневую систему управления памятью:
-
Подсчёт ссылок:
- Быстрый и предсказуемый.
- Не справляется с циклическими ссылками.
-
Циклический сборщик мусора (Generational GC):
- Находит и удаляет "острова" объектов с циклическими ссылками.
- Работает периодически.
Пример циклической ссылки:
a = []
b = [a]
a.append(b) # Теперь a и b ссылаются друг на друга
del a, b # Объекты недостижимы, но ссылки остались
Сборщик мусора найдёт и удалит такие объекты.
Неочевидные особенности Python
1. Изменяемые аргументы по умолчанию
Опасно использовать изменяемые объекты как значения по умолчанию:
def append_to(element, target=[]): # Не делайте так!
target.append(element)
return target
print(append_to(1)) # [1]
print(append_to(2)) # [1, 2] – тот же список!
Правильный подход:
def append_to(element, target=None):
if target is None:
target = []
target.append(element)
return target
2. Ленивые логические операторы
and и or вычисляются лениво:
def expensive_call():
print("Вызов выполнен!")
return True
# expensive_call() не будет вызвана, т.к. первое условие False
if False and expensive_call():
pass
3. Атрибуты функций
Функции в Python — это тоже объекты, и им можно добавлять атрибуты:
def my_func():
pass
my_func.custom_attr = 42
print(my_func.custom_attr) # 42
Заключение
Понимание работы с памятью и объектами в Python — ключ к написанию эффективного и надёжного кода. Помните:
- Используйте
isтолько для сравнения сNone - Для частой конкатенации строк применяйте
join() - Избегайте изменяемых аргументов по умолчанию
- Знайте разницу между изменяемыми и неизменяемыми объектами
Полезные материалы:
- Python Documentation
- Ned Batchelder - Facts and Myths about Python Names and Values
- Real Python - Python Memory Management
Эта глава даёт прочную основу для понимания того, как Python работает "под капотом", что необходимо для написания эффективных и надёжных программ.
Коллекции в Python: от основ к тонкостям
Коллекции — это основа хранения и обработки данных в Python. Понимание их внутреннего устройства, сильных и слабых сторон — ключ к написанию эффективного и идиоматичного кода.
Что такое коллекция?
В Python коллекция — это объект, который одновременно является:
- Контейнером (
Container) — поддерживает операторinдля проверки вхождения. - Итерируемым объектом (
Iterable) — его элементы можно перебирать в цикле. - Объектом ограниченной длины (
Sized) — поддерживает функциюlen().
from collections.abc import Collection
# Проверим, является ли список коллекцией
print(isinstance([1, 2, 3], Collection)) # True
Любопытные исключения
- Интервал чисел может быть контейнером, но не быть итерируемым или иметь длину.
- Генератор является итерируемым, но не контейнером и не имеет длины.
# Пример: Интервал как контейнер
from dataclasses import dataclass
@dataclass
class Interval:
a: float
b: float
def __contains__(self, x):
return self.a < x < self.b
interval = Interval(0, 1)
print(0.5 in interval) # True
print(len(interval)) # TypeError: object of type 'Interval' has no len()
Иерархия коллекций
Стандартная библиотека Python определяет абстрактные базовые классы (ABC) для классификации коллекций:
Container -> Iterable -> Sized -> Collection
|
--------+--------
| |
Sequence Mapping
- Sequence (Последовательности): элементы упорядочены и доступны по индексу (списки, кортежи, строки).
- Mapping (Отображения): хранят пары «ключ-значение» (словари).
Списки (list): универсальные и изменяемые
Списки — это, пожалуй, самая часто используемая коллекция.
Неочевидные особенности инициализации
# Кажется, что это создаст матрицу 2x1
chunks = [[0]] * 2
chunks[0][0] = 42
print(chunks) # [[42], [42]] Оба элемента ссылаются на один и тот же список!
# Правильные способы инициализации матрицы:
correct_chunks = [[0] for _ in range(2)]
correct_chunks = [[0]] * 2 # Так делать нельзя, если планируется изменение вложенных списков!
Эффективные операции
append(item)иpop()— амортизированная сложность O(1).insert(0, item)иpop(0)— сложность O(n), так как требуют сдвига всех элементов.extend(iterable)эффективнее, чем многократный вызовappend().
Совет: Используйте collections.deque, если вам нужны частые операции с обоих концов.
Кортежи (tuple): неизменяемые и хэшируемые
Кортежи не только защищают данные от изменений, но и могут быть использованы как ключи в словарях или элементы множеств, так как они хэшируемы.
Распаковка кортежей — мощный инструмент
# Распаковка с упаковкой «лишних» элементов в переменную
first, second, *rest = range(10)
print(first, second, rest) # 0 1 [2, 3, 4, 5, 6, 7, 8, 9]
# Игнорирование ненужных значений
x, _, z = (1, 2, 3)
# Распаковка в аргументы функции
def greet(name, greeting):
return f"{greeting}, {name}!"
person = ("Alice", "Hello")
print(greet(*person)) # "Hello, Alice!"
Именованные кортежи (namedtuple)
collections.namedtuple — это фабрика классов, создающая подтип кортежа с именованными полями. Это делает код самодокументируемым.
from collections import namedtuple
Point = namedtuple('Point', ['x', 'y'])
p = Point(10, y=20)
print(p.x, p.y) # 10 20
print(p._asdict()) # {'x': 10, 'y': 20}
Множества (set): уникальность и скорость
Множества реализованы как хэш-таблицы, поэтому проверка вхождения (in) имеет среднюю сложность O(1).
Неочевидные применения множеств
-
Удаление дубликатов из списка — классика, но всегда актуально.
unique_list = list(set(duplicated_list)) -
Подсчет общих элементов между двумя коллекциями.
common = set(list1) & set(list2) -
Фильтрация «мусора» при разборе данных.
valid_tags = {'python', 'tutorial', 'advanced'} tags = ['python', 'beginner', 'advanced'] filtered_tags = [tag for tag in tags if tag in valid_tags] # ['python', 'advanced']
frozenset: неизменяемое множество
Поскольку обычные множества изменяемы и, следовательно, нехэшируемы, их нельзя вложить в другие множества или использовать как ключи словаря. Для этого нужен frozenset.
# Множество множеств? Нет.
# {set([1,2]), set([3,4])} # TypeError: unhashable type: 'set'
# А так — можно.
fs1 = frozenset([1, 2])
fs2 = frozenset([3, 4])
meta_set = {fs1, fs2} # Valid
Словари (dict): сердце Python
Современные словари (Python 3.7+) сохраняют порядок добавления элементов.
Малоизвестные возможности словарей
-
Метод
setdefault()— проверяет наличие ключа и, если его нет, устанавливает значение за один проход по хэш-таблице.data = {} # Классический, но неэффективный способ if 'key' not in data: data['key'] = [] data['key'].append(1) # Эффективный способ с setdefault data.setdefault('key', []).append(1) -
Метод
popitem()— удаляет и возвращает пару(ключ, значение)в порядке LIFO (последним пришел — первым ушел). Полезно для обработки данных в обратном порядке. -
Словарные включения (Dict Comprehensions) — компактный и выразительный синтаксис.
squares = {x: x*x for x in range(5)} # {0: 0, 1: 1, 2: 4, 3: 9, 4: 16}
Коллекции из модуля collections
Модуль collections предоставляет специализированные типы данных, которые расширяют возможности стандартных коллекций.
-
defaultdict— словарь с заводской функцией для отсутствующих ключей.from collections import defaultdict graph = defaultdict(list) graph['a'].append('b') # Не нужно проверять, есть ли ключ 'a' -
Counter— подкласс словаря для подсчета хэшируемых объектов.from collections import Counter words = ['apple', 'banana', 'apple', 'orange'] word_count = Counter(words) print(word_count.most_common(1)) # [('apple', 2)] -
deque— двусторонняя очередь. Идеальна для очередей (FIFO) и стеков (LIFO).from collections import deque queue = deque([1, 2, 3]) queue.append(4) # O(1) queue.popleft() # O(1) - в отличие от списка! -
OrderedDict— словарь, который помнит порядок. В Python 3.7+ обычныйdictтоже упорядочен, ноOrderedDictимеет дополнительные методы (move_to_end,popitem(last=True/False)).
Заключение
Выбор правильной коллекции — это не просто вопрос синтаксиса. Это вопрос эффективности, читаемости и корректности вашего кода.
- Используйте списки для упорядоченных коллекций, которые могут изменяться.
- Используйте кортежи для фиксированных данных или когда нужны хэшируемые объекты.
- Используйте множества для проверки уникальности и быстрого поиска.
- Используйте словари для отображений ключей на значения.
- Не забывайте о специализированных коллекциях из модуля
collectionsдля решения специфических задач.
Глубокое понимание коллекций позволит вам писать код, который не только работает, но и работает хорошо.
Сложность операций с коллекциями
Понимание временной сложности операций — ключ к написанию эффективных программ. В нотации O-большое мы описываем, как время выполнения алгоритма растет с ростом размера входных данных.
Почему сложность важна?
from timeit import timeit
import random
# Сравним поиск в списке и множестве
large_list = list(range(1000000))
large_set = set(large_list)
# Ищем случайный элемент
target = random.randint(0, 1000000)
# Время поиска в списке (O(n))
list_time = timeit(lambda: target in large_list, number=1000)
# Время поиска в множестве (O(1))
set_time = timeit(lambda: target in large_set, number=1000)
print(f"Поиск в списке: {list_time:.4f} сек")
print(f"Поиск в множестве: {set_time:.4f} сек")
Результат будет поразительным — поиск в множестве в тысячи раз быстрее!
Сложность операций со списками
O(1) — Константное время
my_list = [1, 2, 3, 4, 5]
# Эти операции выполняются за постоянное время
my_list.append(6) # Добавление в конец
last = my_list.pop() # Удаление с конца
element = my_list[2] # Доступ по индексу
length = len(my_list) # Получение длины
Почему O(1): Python хранит указатель на последний элемент, поэтому добавление/удаление с конца не требует перемещения других элементов.
O(n) — Линейное время
my_list = [1, 2, 3, 4, 5]
# Эти операции требуют обхода или сдвига элементов
my_list.insert(0, 0) # Вставка в начало → сдвиг всех элементов
my_list.remove(3) # Поиск и удаление элемента
element in my_list # Поиск элемента
my_list.index(4) # Поиск индекса элемента
Почему O(n): При вставке в начало все последующие элементы должны быть сдвинуты на одну позицию.
Практический пример: неэффективный vs эффективный код
# НЕЭФФЕКТИВНО: O(n²)
def remove_duplicates_slow(data):
result = []
for item in data:
if item not in result: # O(n) для каждого элемента!
result.append(item)
return result
# ЭФФЕКТИВНО: O(n)
def remove_duplicates_fast(data):
seen = set()
result = []
for item in data:
if item not in seen: # O(1) проверка!
seen.add(item)
result.append(item)
return result
# Тестируем
data = [1, 2, 2, 3, 4, 4, 5] * 1000
slow_time = timeit(lambda: remove_duplicates_slow(data), number=1)
fast_time = timeit(lambda: remove_duplicates_fast(data), number=1)
print(f"Медленная версия: {slow_time:.4f} сек")
print(f"Быстрая версия: {fast_time:.4f} сек")
Сложность операций с множествами
Множества реализованы как хэш-таблицы, поэтому большинство операций имеют сложность O(1).
my_set = {1, 2, 3, 4, 5}
# O(1) операции
my_set.add(6) # Добавление
my_set.remove(3) # Удаление
4 in my_set # Проверка вхождения
len(my_set) # Длина
# O(min(len(s1), len(s2))) операции
s1 = {1, 2, 3}
s2 = {3, 4, 5}
union = s1 | s2 # Объединение
intersection = s1 & s2 # Пересечение
difference = s1 - s2 # Разность
Интересный факт: Худший случай для операций с множествами — O(n), когда происходят коллизии хэшей, но на практике это редкая ситуация.
Сложность операций со словарями
Словари также используют хэш-таблицы, поэтому основные операции имеют сложность O(1).
my_dict = {'a': 1, 'b': 2, 'c': 3}
# O(1) операции
my_dict['d'] = 4 # Вставка/обновление
value = my_dict['a'] # Доступ
del my_dict['b'] # Удаление
'a' in my_dict # Проверка ключа
# O(n) операции
list(my_dict.keys()) # Создание списка ключей
list(my_dict.values()) # Создание списка значений
'value' in my_dict.values() # Поиск по значениям
Как вычислять сложность на практике
Метод 1: Анализ вложенных циклов
# O(n²) — квадратичная сложность
def find_pairs_quadratic(items):
pairs = []
for i in range(len(items)): # O(n)
for j in range(i + 1, len(items)): # O(n)
pairs.append((items[i], items[j])) # O(1)
return pairs
# O(n) — линейная сложность
def find_pairs_linear(items):
pairs = []
seen = set()
for i, item in enumerate(items): # O(n)
if item not in seen: # O(1)
seen.add(item)
# некоторая логика
return pairs
Метод 2: Учет дорогостоящих операций
def process_data(data):
result = []
# Сортировка: O(n log n)
sorted_data = sorted(data) # O(n log n)
# Поиск каждого элемента: O(n) × O(log n) = O(n log n)
for target in sorted_data: # O(n)
# Бинарный поиск: O(log n)
# (предположим, что у нас есть реализация)
index = binary_search(sorted_data, target)
result.append(index)
return result
# Общая сложность: O(n log n) + O(n log n) = O(n log n)
Метод 3: Практическое измерение
import time
import matplotlib.pyplot as plt
def measure_complexity():
sizes = [1000, 2000, 4000, 8000, 16000]
times = []
for size in sizes:
data = list(range(size))
start = time.time()
# Тестируемая операция
_ = data.insert(0, -1) # O(n) операция
end = time.time()
times.append(end - start)
# Строим график для визуальной оценки
plt.plot(sizes, times)
plt.xlabel('Размер данных')
plt.ylabel('Время выполнения')
plt.show()
# measure_complexity() # График покажет линейный рост для O(n)
Практические правила для выбора коллекций
Когда использовать списки:
- Нужен последовательный доступ к элементам
- Частые операции с концом списка (append/pop)
- Элементы могут дублироваться
- Избегайте: частых insert(0)/pop(0) на больших данных
Когда использовать множества:
- Проверка принадлежности (x in collection)
- Удаление дубликатов
- Математические операции (объединение, пересечение)
- Избегайте: сохранения порядка или хранения нехэшируемых объектов
Когда использовать словари:
- Ассоциативное хранение данных (ключ→значение)
- Быстрый поиск по ключу
- Группировка данных
- Избегайте: частого поиска по значениям (используйте обратный словарь)
Оптимизация на практике
# ПЛОХО: O(n²)
def find_common_elements_slow(list1, list2):
result = []
for item in list1: # O(n)
if item in list2: # O(m) - линейный поиск!
result.append(item)
return result
# ХОРОШО: O(n + m)
def find_common_elements_fast(list1, list2):
set2 = set(list2) # O(m) - создание множества
result = []
for item in list1: # O(n)
if item in set2: # O(1) - поиск в хэш-таблице!
result.append(item)
return result
Некоторые правила сложности
- O(1) < O(log n) < O(n) < O(n log n) < O(n²) — запомните эту иерархию
- Избегайте вложенных циклов — они часто приводят к O(n²)
- Используйте правильные структуры данных — множества и словари для поиска, списки для последовательностей
Помните: преждевременная оптимизация может быть вредна, но понимание сложности операций поможет вам избежать грубых ошибок в дизайне алгоритмов.
Функции в Python
Синтаксис объявления функций
Базовый синтаксис
Имя функции в Python может содержать буквы, цифры и символ подчеркивания _, но не может начинаться с цифры:
def foo():
return 42
foo() # возвращает 42
Важно: оператор return не обязателен. Если его нет, функция возвращает None:
def foo():
42
print(foo()) # выводит None
Документирование функций
Для документирования используются строковые литералы (docstring):
def foo():
"""I return 42."""
return 42
Документация доступна через атрибут __doc__ или функцию help():
print(foo.__doc__) # 'I return 42.'
help(foo) # показывает документацию
Работа с аргументами
Позиционные и именованные аргументы
def min(x, y):
return x if x < y else y
min(-5, 12) # -5
min(x=-5, y=12) # -5
min(y=12, x=-5) # -5 (порядок не важен)
Упаковка позиционных аргументов
Для работы с произвольным количеством аргументов используется *args:
def min(*args):
res = float("inf")
for arg in args:
if arg < res:
res = arg
return res
min(-5, 12, 13) # -5
min() # inf
Обязательный первый аргумент:
def min(first, *args):
res = first
for arg in args:
if arg < res:
res = arg
return res
min() # TypeError: missing required argument 'first'
Распаковка аргументов
Синтаксис распаковки работает с любыми итерируемыми объектами:
xs = {-5, 12, 13}
min(*xs) # -5
min(*[-5, 12, 13]) # -5
min(*(-5, 12, 13)) # -5
Ключевые аргументы и значения по умолчанию
def bounded_min(first, *args, lo=float("-inf"), hi=float("inf")):
res = hi
for arg in (first,) + args:
if arg < res and lo < arg < hi:
res = arg
return max(res, lo)
bounded_min(-5, 12, 13, lo=0, hi=255) # 12
Опасность изменяемых значений по умолчанию
Неправильно:
def unique(iterable, seen=set()):
acc = []
for item in iterable:
if item not in seen:
seen.add(item)
acc.append(item)
return acc
xs = [1, 1, 2, 3]
unique(xs) # [1, 2, 3]
unique(xs) # [] 😱
Правильно:
def unique(iterable, seen=None):
seen = set(seen or []) # None - falsy значение
acc = []
for item in iterable:
if item not in seen:
seen.add(item)
acc.append(item)
return acc
xs = [1, 1, 2, 3]
unique(xs) # [1, 2, 3]
unique(xs) # [1, 2, 3] ✅
Только ключевые аргументы
Можно требовать, чтобы некоторые аргументы передавались только по имени:
def flatten(xs, *, depth=None):
pass
flatten([1, [2], 3], depth=1) # ✅
flatten([1, [2], 3], 1) # TypeError
Упаковка ключевых аргументов
def runner(cmd, **kwargs):
if kwargs.get("verbose", True):
print("Logging enabled")
runner("mysqld", limit=42) # ✅
runner("mysqld", **{"verbose": False}) # ✅
options = {"verbose": False}
runner("mysqld", **options) # ✅
Распаковка и присваивание
Базовая распаковка
x, y, z = [1, 2, 3] # ✅
x, y, z = {1, 2, 3} # ✅ (но порядок не гарантирован!)
x, y, z = "xyz" # ✅
# Распаковка вложенных структур
rectangle = (0, 0), (4, 4)
(x1, y1), (x2, y2) = rectangle
Расширенная распаковка (Python 3.0+)
first, *rest = range(1, 5) # first=1, rest=[2, 3, 4]
first, *rest, last = range(1, 5) # first=1, rest=[2, 3], last=4
# Можно использовать в любом месте
*_, (first, *rest) = [range(1, 5)] * 5
Особенность: при недостатке значений возникает ошибка:
first, *rest, last = [42] # ValueError
Распаковка в цикле for
for a, *b in [range(4), range(2)]:
print(b)
# Вывод:
# [1, 2, 3]
# [1]
Области видимости (Scopes)
Функции внутри функций
Функции в Python — объекты первого класса:
def wrapper():
def identity(x):
return x
return identity
f = wrapper()
f(42) # 42
Правило LEGB
Поиск имен осуществляется в четырех областях видимости:
- Local (локальная)
- Enclosing (объемлющая)
- Global (глобальная)
- Built-in (встроенная)
min = 42 # global
def f(*args):
min = 2 # enclosing
def g():
min = 4 # local
print(min)
Замыкания и позднее связывание
Замыкания используют переменные из внешних областей видимости во время выполнения:
def f():
print(i)
for i in range(4):
f()
# Вывод:
# 0
# 1
# 2
# 3
Присваивание и области видимости
По умолчанию присваивание создает локальную переменную:
min = 42
def f():
min += 1 # UnboundLocalError!
return min
Оператор global
Позволяет изменять глобальные переменные:
min = 42
def f():
global min
min += 1
return min
f() # 43
f() # 44
Оператор nonlocal (Python 3+)
Позволяет изменять переменные из объемлющей области видимости:
def cell(value=None):
def get():
return value
def set(update):
nonlocal value
value = update
return get, set
get, set = cell()
set(42)
get() # 42
Функциональное программирование
Анонимные функции (lambda)
lambda arguments: expression
# Эквивалентно:
def <lambda>(arguments):
return expression
Примеры:
lambda x: x ** 2
lambda foo, *args, bar=None, **kwargs: 42
Функции map, filter, zip
map - применяет функцию к каждому элементу:
list(map(lambda x: x % 7, [1, 9, 16, -1, 2, 5])) # [1, 2, 2, 6, 2, 5]
filter - оставляет элементы, удовлетворяющие условию:
list(filter(lambda x: x % 2 != 0, range(10))) # [1, 3, 5, 7, 9]
# С None - оставляет только truthy значения
xs = [0, None, [], {}, set(), "", 42]
list(filter(None, xs)) # [42]
zip - объединяет элементы нескольких последовательностей:
list(zip("abc", range(3), [42j, 42j, 42j]))
# [('a', 0, 42j), ('b', 1, 42j), ('c', 2, 42j)]
Генераторы коллекций
Генераторы списков:
[x ** 2 for x in range(10) if x % 2 == 1] # [1, 9, 25, 49, 81]
# Эквивалент с map/filter:
list(map(lambda x: x ** 2, filter(lambda x: x % 2 == 1, range(10))))
# Вложенные генераторы:
nested = [range(5), range(8, 10)]
[x for xs in nested for x in xs] # [0, 1, 2, 3, 4, 8, 9]
Генераторы множеств и словарей:
{x % 7 for x in [1, 9, 16, -1, 2, 5]} # {1, 2, 5, 6}
date = {'year': 2014, "month": "September", "day": ""}
{k: v for k, v in date.items() if v} # {'year': 2014, 'month': 'September'}
{x: x ** 2 for x in range(4)} # {0: 0, 1: 1, 2: 4, 3: 9}
PEP 8: стиль кода
Базовые рекомендации
- 4 пробела для отступов
- Максимум 79 символов в строке кода
lower_case_with_underscoresдля переменных и функцийUPPER_CASE_WITH_UNDERSCORESдля констант
Выражения и операторы
Правильно:
exp = -1.05
value = (item_value / item_count) * offset / exp
if bar:
x += 1
if method == 'md5':
pass
if key not in d:
pass
Неправильно:
if bar: x += 1
if 'md5' == method:
pass
if not key in d:
pass
Функции
def something_useful(arg, **options):
"""One-line summary.
Optional longer description.
"""
pass
Резюме
- Функции могут принимать произвольное количество позиционных (
*args) и ключевых (**kwargs) аргументов - Синтаксис распаковки работает в вызовах функций, присваивании и циклах
- Поиск имен осуществляется по правилу LEGB
- Присваивание создает локальные переменные (можно изменить через
global/nonlocal) - Python поддерживает элементы ФП: lambda, map, filter, zip, генераторы коллекций
- PEP 8 содержит стилистические рекомендации для написания читаемого кода
Декораторы и модуль functools
Декораторы в Python — это мощный инструмент для модификации поведения функций и методов, позволяющий писать чистый, повторно используемый и легко читаемый код. В этой главе мы глубоко погрузимся в мир декораторов, изучим их синтаксис, создание, применение, а также познакомимся с полезными инструментами из модуля functools.
Синтаксис декораторов
Декоратор — это функция, которая принимает другую функцию и возвращает новую функцию (или любой другой объект). Синтаксис декоратора — это «синтаксический сахар», который делает код более понятным.
@decorator
def foo(x):
return 42
Эквивалентно:
def foo(x):
return 42
foo = decorator(foo)
Таким образом, после применения декоратора имя foo будет ссылаться на результат вызова decorator(foo).
«Теория» декораторов: создание простого декоратора
Рассмотрим пример декоратора trace, который логирует вызовы функции:
def trace(func):
def inner(*args, **kwargs):
print(func.__name__, args, kwargs)
return func(*args, **kwargs)
return inner
Применим его:
@trace
def identity(x):
"I do nothing useful."
return x
identity(42) # Вывод: identity (42,) {} → 42
Проблема атрибутов функции
После применения декоратора исходные атрибуты функции (такие как __name__, __doc__) теряются:
identity.__name__ # 'inner'
help(identity) # Справка о inner, а не identity
Решение: functools.wraps
Модуль functools предоставляет декоратор wraps, который копирует метаданные исходной функции в декорированную:
import functools
def trace(func):
@functools.wraps(func)
def inner(*args, **kwargs):
print(func.__name__, args, kwargs)
return func(*args, **kwargs)
return inner
Теперь identity.__name__ и help(identity) работают корректно.
Декораторы с аргументами
Иногда нужно параметризовать декоратор. Например, указать файл для вывода в trace:
def trace(handle):
def decorator(func):
@functools.wraps(func)
def inner(*args, **kwargs):
print(func.__name__, args, kwargs, file=handle)
return func(*args, **kwargs)
return inner
return decorator
@trace(sys.stderr)
def identity(x):
return x
Эквивалентно:
decorator = trace(sys.stderr)
identity = decorator(identity)
Декораторы с опциональными аргументами
Чтобы декоратор можно было использовать как с аргументами, так и без них, применяют следующий паттерн:
def trace(func=None, *, handle=sys.stdout):
if func is None:
return lambda func: trace(func, handle=handle)
@functools.wraps(func)
def inner(*args, **kwargs):
print(func.__name__, args, kwargs, file=handle)
return func(*args, **kwargs)
return inner
Использование:
@trace
def foo(): ...
@trace(handle=sys.stderr)
def bar(): ...
Зачем только ключевые аргументы? Это предотвращает неоднозначность при вызове и делает код чище.
Практика: полезные декораторы
@timethis — замер времени выполнения
import time
def timethis(func=None, *, n_iter=100):
if func is None:
return lambda func: timethis(func, n_iter=n_iter)
@functools.wraps(func)
def inner(*args, **kwargs):
print(func.__name__, end=" ... ")
acc = float("inf")
for i in range(n_iter):
tick = time.perf_counter()
result = func(*args, **kwargs)
acc = min(acc, time.perf_counter() - tick)
print(acc)
return result
return inner
@once — выполнить не более одного раза
def once(func):
@functools.wraps(func)
def inner(*args, **kwargs):
if not inner.called:
inner.result = func(*args, **kwargs)
inner.called = True
return inner.result
inner.called = False
return inner
@memoized — мемоизация
def memoized(func):
cache = {}
@functools.wraps(func)
def inner(*args, **kwargs):
key = args + tuple(sorted(kwargs.items()))
if key not in cache:
cache[key] = func(*args, **kwargs)
return cache[key]
return inner
Проблема: Словари нехэшируемы. Для универсального решения можно сериализовать аргументы в строку (например, через pickle).
@deprecated — пометить функцию как устаревшую
import warnings
def deprecated(func):
code = func.__code__
warnings.warn_explicit(
f"{func.__name__} is deprecated.",
category=DeprecationWarning,
filename=code.co_filename,
lineno=code.co_firstlineno + 1
)
return func
Контрактное программирование с декораторами
Реализуем простые контракты @pre и @post:
def pre(cond, message):
def decorator(func):
@functools.wraps(func)
def inner(*args, **kwargs):
assert cond(*args, **kwargs), message
return func(*args, **kwargs)
return inner
return decorator
def post(cond, message):
def decorator(func):
@functools.wraps(func)
def inner(*args, **kwargs):
result = func(*args, **kwargs)
assert cond(result), message
return result
return inner
return decorator
Использование:
@pre(lambda x: x >= 0, "negative argument")
@post(lambda r: not math.isnan(r), "result is NaN")
def log_positive(x):
return math.log(x)
Цепочки декораторов
Порядок применения декораторов имеет значение:
@deco1
@deco2
def foo(): ...
Эквивалентно:
foo = deco1(deco2(foo))
Модуль functools
lru_cache — мемоизация с ограничением
@functools.lru_cache(maxsize=128)
def expensive_func(x):
return x * x
maxsize=None— неограниченный кэш (опасно при большом количестве вызовов!).cache_info()— статистика использования кэша.
partial — частичное применение
f = functools.partial(sorted, key=lambda x: x[1])
f([('a', 4), ('b', 2)]) # [('b', 2), ('a', 4)]
singledispatch — обобщённые функции
Позволяет определять разные реализации функции для разных типов:
@functools.singledispatch
def pack(obj):
raise TypeError(f"Unsupported type: {type(obj)}")
@pack.register(int)
def _(obj):
return b"I" + hex(obj).encode("ascii")
@pack.register(list)
def _(obj):
return b"L" + b",".join(map(pack, obj))
reduce — свёртка последовательности
functools.reduce(lambda acc, x: acc * x, [1, 2, 3, 4]) # 24
Хотя reduce популярен в функциональных языках, в Python его используют редко, предпочитая явные циклы для ясности.
Заключение
Декораторы — это не просто «синтаксический сахар», а фундаментальный инструмент метапрограммирования в Python. Они позволяют:
- Модифицировать поведение функций без изменения их кода.
- Реализовывать аспектно-ориентированное программирование.
- Создавать выразительные и легко читаемые API.
Модуль functools предоставляет готовые решения для многих задач, связанных с функциональным программированием и декорированием.
Дополнительные материалы:
- Python Decorator Library
- PEP 443 – Single-dispatch generic functions
- PEP 318 – Decorators for Functions and Methods
Классы в Python
Введение
Классы в Python предоставляют средства для объектно-ориентированного программирования. В отличие от языков вроде Java и C++, Python использует явную передачу ссылки на экземпляр через параметр self.
💡 Интересный факт: Python был одним из первых языков, где объектно-ориентированность была заложена в основу дизайна с самого начала. В отличие от C++, где ООП добавлялось постепенно, или Java, где всё должно быть в классах, Python находит баланс между процедурным и объектно-ориентированным подходами.
Базовые понятия
Определение класса
class Counter:
"""I count. That is all."""
def __init__(self, initial=0): # конструктор
self.value = initial # запись атрибута
def increment(self):
self.value += 1
def get(self):
return self.value # чтение атрибута
# Использование
c = Counter(42)
c.increment()
print(c.get()) # 43
💡 Интересный факт: Название __init__ может вводить в заблуждение - это не конструктор в традиционном понимании. Настоящий конструктор - это метод __new__, который создаёт объект, а __init__ лишь инициализирует уже созданный объект. Это различие важно при наследовании от неизменяемых типов.
Специфика Python
- Первый аргумент методов — всегда
self(явная передача экземпляра) - Нет модификаторов доступа, но есть соглашения об именовании:
public_attribute— публичный атрибут_internal_attribute— внутренний атрибут (одиночное подчеркивание)__private_attribute— приватный атрибут (двойное подчеркивание, реализуется через name mangling)
💡 Интересный факт: Соглашение об именовании с подчеркиваниями — это пример "соглашения между джентльменами" в Python. Технически вы всё равно можете получить доступ к "приватным" атрибутам, но так делать не рекомендуется. Name mangling преобразует __private в _ClassName__private, что помогает избежать конфликтов имен в подклассах.
Атрибуты классов и экземпляров
Атрибуты экземпляра
Добавляются через присваивание к self:
class Noop:
def __init__(self):
self.some_attribute = 42
noop = Noop()
noop.other_attribute = 100500 # динамическое добавление
💡 Интересный факт: Python позволяет динамически добавлять атрибуты к уже созданным объектам благодаря тому, что атрибуты хранятся в обычном словаре __dict__. Это даёт большую гибкость, но может приводить к трудноуловимым багам, если вы опечатаетесь в имени атрибута.
Атрибуты класса
class Counter:
all_counters = [] # атрибут класса
def __init__(self, initial=0):
Counter.all_counters.append(self)
self.value = initial
# Также можно добавлять атрибуты после определения
Counter.some_other_attribute = 42
💡 Интересный факт: Атрибуты класса разделяются между всеми экземплярами. Это может быть как полезным (для шаблона "Моносостояние"), так и опасным - если вы изменяете изменяемый атрибут класса, это повлияет на все экземпляры!
Словарь атрибутов
noop = Noop()
noop.some_attribute = 42
print(noop.__dict__) # {'some_attribute': 42}
print(vars(noop)) # альтернативный способ
# Динамическое управление атрибутами
noop.__dict__["dynamic_attr"] = "value"
💡 Интересный факт: Функция vars() без аргументов возвращает __dict__ текущего локального пространства имен, а с одним аргументом - __dict__ этого объекта. Это один из многих примеров того, как Python делает внутренние механизмы доступными для программиста.
__slots__ для оптимизации
class Noop:
__slots__ = ["some_attribute"] # фиксирует набор атрибутов
def __init__(self):
self.some_attribute = 42
# Экономит память, но запрещает добавление новых атрибутов
💡 Интересный факт: Использование __slots__ может сократить потребление памяти на 40-50% для объектов с небольшим количеством атрибутов, поскольку исключает необходимость в словаре __dict__. Однако это ограничивает гибкость и делает невозможным использование некоторых возможностей, таких как weak references, без явного указания.
Методы
Связанные и несвязанные методы
class SomeClass:
def do_something(self):
print("Doing something.")
# Несвязанный метод
method = SomeClass.do_something
instance = SomeClass()
method(instance) # нужно явно передать экземпляр
# Связанный метод
bound_method = instance.do_something
bound_method() # self уже привязан
💡 Интересный факт: В Python 2 методы были отдельным типом (unbound method), который проверял тип первого аргумента. В Python 3 несвязанный метод - это просто функция, что делает приведенный выше код работоспособным. Это изменение упростило многие сценарии метапрограммирования.
Свойства (Properties)
Свойства позволяют контролировать доступ к атрибутам:
class BigDataModel:
def __init__(self):
self._params = []
@property
def params(self):
return self._params
@params.setter
def params(self, new_params):
assert all(p > 0 for p in new_params)
self._params = new_params
@params.deleter
def params(self):
del self._params
model = BigDataModel()
model.params = [0.1, 0.5, 0.4]
print(model.params) # [0.1, 0.5, 0.4]
💡 Интересный факт: Свойства - это пример паттерна "Uniform Access Principle", который позволяет заменить поле на метод без изменения клиентского кода. В Python это реализовано через дескрипторы, что делает свойства гораздо более мощными, чем аналогичные механизмы в других языках.
Наследование
Базовое наследование
class Counter:
def __init__(self, initial=0):
self.value = initial
class OtherCounter(Counter):
def get(self):
return self.value
oc = OtherCounter() # вызывает Counter.__init__
print(oc.get()) # вызывает OtherCounter.get
💡 Интересный факт: Python поддерживает множественное наследование, что редко встречается в других языках. Хотя это мощная возможность, она может приводить к сложностям с порядком разрешения методов (MRO).
Перегрузка методов и super()
class Counter:
all_counters = []
def __init__(self, initial=0):
self.__class__.all_counters.append(self)
self.value = initial
class OtherCounter(Counter):
def __init__(self, initial=0):
self.initial = initial
super().__init__(initial) # вызов родительского конструктора
💡 Интересный факт: Функция super() в Python 3 стала значительно умнее, чем в Python 2. Она автоматически определяет нужный класс и экземпляр, что особенно важно при множественном наследовании. Под капотом она использует MRO (Method Resolution Order), вычисляемый алгоритмом C3.
Множественное наследование
class A:
def f(self):
print("A.f")
class B:
def f(self):
print("B.f")
class C(A, B):
pass
print(C.mro()) # порядок разрешения методов
C().f() # A.f (согласно MRO)
💡 Интересный факт: Алгоритм C3 для разрешения порядка методов был заимствован из языка Dylan. Он гарантирует, что:
- Подклассы имеют приоритет над суперклассами
- Порядок в списке наследования сохраняется
- Все классы в иерархии будут посещены
Классы-примеси
class ThreadSafeMixin:
def get_lock(self):
# возвращает объект блокировки
pass
def increment(self):
with self.get_lock():
super().increment()
def get(self):
with self.get_lock():
return super().get()
class ThreadSafeCounter(ThreadSafeMixin, Counter):
pass
💡 Интересный факт: Примеси (mixins) - это способ реализовать композицию в мире наследования. Они широко используются в Django и других фреймворках для добавления функциональности без создания глубоких иерархий наследования. Ключевая особенность - вызов super(), который работает даже если следующий класс в MRO неизвестен на момент написания кода.
Декораторы классов
def singleton(cls):
instance = None
@functools.wraps(cls)
def inner(*args, **kwargs):
nonlocal instance
if instance is None:
instance = cls(*args, **kwargs)
return instance
return inner
@singleton
class Noop:
"I do nothing at all."
print(id(Noop()) == id(Noop())) # True
💡 Интересный факт: Декораторы классов были добавлены в Python 3.0 (PEP 3129). Они позволяют применять к классам те же техники трансформации, что и к функциям. Многие паттерны, которые раньше требовали метаклассов, теперь можно реализовать с помощью декораторов классов.
Магические методы
Управление атрибутами
class Noop:
def __getattr__(self, name):
# Вызывается при доступе к несуществующему атрибуту
return f"Attribute {name} doesn't exist"
def __setattr__(self, name, value):
# Вызывается при установке любого атрибута
super().__setattr__(name, value)
def __delattr__(self, name):
# Вызывается при удалении атрибута
super().__delattr__(name)
noop = Noop()
print(noop.non_existent) # "Attribute non_existent doesn't exist"
💡 Интересный факт: Важно различать __getattr__ и __getattribute__. Первый вызывается только для отсутствующих атрибутов, второй - для всех. Использование __getattribute__ требует особой осторожности, так как неправильная реализация может привести к бесконечной рекурсии.
Операторы сравнения
import functools
@functools.total_ordering
class Counter:
def __init__(self, value):
self.value = value
def __eq__(self, other):
return self.value == other.value
def __lt__(self, other):
return self.value < other.value
c1, c2 = Counter(1), Counter(2)
print(c1 < c2) # True
print(c1 >= c2) # False (автоматически из __lt__ и __eq__)
💡 Интересный факт: Декоратор @total_ordering из модуля functools генерирует все методы сравнения на основе __eq__ и одного из методов упорядочивания. Это пример того, как Python старается уменьшить boilerplate код, оставаясь при этом явным и понятным.
Строковое представление
class Counter:
def __init__(self, initial=0):
self.value = initial
def __repr__(self):
return f"Counter({self.value})"
def __str__(self):
return f"Counted to {self.value}"
def __format__(self, format_spec):
return self.value.__format__(format_spec)
c = Counter(42)
print(repr(c)) # Counter(42)
print(str(c)) # Counted to 42
print(f"{c:b}") # 101010 (бинарное представление)
💡 Интересный факт: Соглашение в Python: __repr__ должен быть однозначным и по возможности возвращать строку, которую можно использовать для воссоздания объекта, а __str__ должен быть читаемым. Если __str__ не определен, используется __repr__.
Другие полезные магические методы
class Identity:
def __call__(self, x):
# Позволяет вызывать экземпляры как функции
return x
def __bool__(self):
# Определяет поведение в булевом контексте
return True
def __hash__(self):
# Используется для хеширования в словарях и множествах
return hash(id(self))
identity = Identity()
print(identity(42)) # 42
💡 Интересный факт: Метод __call__ делает объекты вызываемыми, что является основой для создания декораторов на основе классов. Это демонстрирует философию Python, где функции и объекты не так сильно различаются - всё является объектами, а некоторые объекты можно вызывать.
Дескрипторы
Дескрипторы позволяют переиспользовать логику свойств:
Базовый дескриптор
class NonNegative:
def __get__(self, instance, owner):
# magically_get_value
pass
def __set__(self, instance, value):
assert value >= 0, "non-negative value required"
# magically_set_value
def __delete__(self, instance):
# magically_delete_value
pass
class VerySafe:
x = NonNegative()
y = NonNegative()
very_safe = VerySafe()
very_safe.x = 42 # OK
very_safe.x = -42 # AssertionError
💡 Интересный факт: Дескрипторы - это один из самых мощных, но малоизвестных механизмов Python. Функции, свойства, статические методы и методы класса - всё это реализовано через дескрипторы. Протокол дескрипторов позволяет перехватывать доступ к атрибутам на уровне класса.
Хранение данных в дескрипторах
class Proxy:
def __init__(self, label):
self.label = label
def __get__(self, instance, owner):
return instance.__dict__[self.label]
def __set__(self, instance, value):
instance.__dict__[self.label] = value
def __delete__(self, instance):
del instance.__dict__[self.label]
class Something:
attr = Proxy("attr")
some = Something()
some.attr = 42
print(some.attr) # 42
💡 Интересный факт: Хранение данных в __dict__ экземпляра - это наиболее правильный способ реализации дескрипторов данных. Альтернативные подходы (хранение в атрибутах дескриптора или в отдельном словаре) имеют серьезные недостатки: первый нарушает работу с несколькими экземплярами, второй требует hashable объекты и может приводить к утечкам памяти.
Встроенные дескрипторы
# @property реализован через дескрипторы
class property:
def __init__(self, get=None, set=None, delete=None):
self._get = get
self._set = set
self._delete = delete
def __get__(self, instance, owner):
if self._get is None:
raise AttributeError("unreadable attribute")
return self._get(instance)
# @staticmethod и @classmethod тоже используют дескрипторы
class staticmethod:
def __init__(self, method):
self.__method = method
def __get__(self, instance, owner):
return self.__method
class classmethod:
def __init__(self, method):
self.__method = method
def __get__(self, instance, owner):
if owner is None:
owner = type(instance)
return self.__method.__get__(owner, type(owner))
💡 Интересный факт: Разница между статическими методами и методами класса именно в реализации их дескрипторов. Статический метод просто возвращает исходную функцию, а метод класса привязывается к классу. Это демонстрирует, как мощные абстракции в Python строятся из простых механизмов.
Метаклассы
Метаклассы — это классы, экземпляры которых тоже классы.
Базовый метакласс
class Meta(type):
def __new__(metacls, name, bases, clsdict):
print(f"Creating class {name}")
cls = super().__new__(metacls, name, bases, clsdict)
return cls
@classmethod
def __prepare__(metacls, name, bases):
# Может вернуть нестандартный mapping для clsdict
return OrderedDict()
class Something(metaclass=Meta):
attr = "foo"
other_attr = "bar"
💡 Интересный факт: Метод __prepare__ позволяет контролировать тип объекта, который используется для хранения атрибутов класса во время его создания. Это может быть использовано для сохранения порядка объявления атрибутов, добавления дополнительной валидации или логирования.
Создание классов через type()
# Эквивалентно class Something: attr = 42
name, bases, attrs = "Something", (), {"attr": 42}
Something = type(name, bases, attrs)
some = Something()
print(some.attr) # 42
💡 Интересный факт: Оператор class в Python - это синтаксический сахар для вызова type() с соответствующими аргументами. Это демонстрирует консистентность Python: даже такие фундаментальные конструкции реализованы через вызовы функций.
Модуль abc для абстрактных базовых классов
import abc
class Iterable(metaclass=abc.ABCMeta):
@abc.abstractmethod
def __iter__(self):
pass
class Something(Iterable):
pass
# Something() # TypeError: Can't instantiate abstract class
💡 Интересный факт: Абстрактные базовые классы (ABC) были добавлены в Python для обеспечения более строгой проверки интерфейсов. В отличие от Java, где интерфейсы являются отдельной конструкцией, в Python они реализованы через обычные классы с метаклассом ABCMeta, что сохраняет согласованность языка.
Модуль collections.abc
Полезен для создания собственных коллекций:
from collections.abc import MutableMapping
class MemorizingDict(MutableMapping):
def __init__(self, *args, **kwargs):
self._data = dict(*args, **kwargs)
self._history = deque(maxlen=10)
def __getitem__(self, key):
return self._data[key]
def __setitem__(self, key, value):
self._history.append(key)
self._data[key] = value
def __delitem__(self, key):
del self._data[key]
def __iter__(self):
return iter(self._data)
def __len__(self):
return len(self._data)
def get_history(self):
return self._history
💡 Интересный факт: Модуль collections.abc содержит абстрактные базовые классы для встроенных типов коллекций. Наследование от этих классов гарантирует, что ваша кастомная коллекция будет совместима с ожиданиями Python и других библиотек. Например, если вы реализуете __getitem__ и __len__, вы автоматически получаете поддержку iter() и проверку на вхождение с помощью in.
Заключение
Классы в Python предоставляют мощные и гибкие средства для объектно-ориентированного программирования. От базовых концепций наследования и инкапсуляции до продвинутых возможностей вроде дескрипторов и метаклассов — Python предлагает богатый инструментарий для создания сложных и поддерживаемых программных систем.
💡 Интересный факт: Философия Python в отношении ООП хорошо выражена в цитате Тим Петерса (автора The Zen of Python): "ООП делает код понятным для компьютера, но не для программиста. Хороший код должен быть понятен и тому, и другому." Python находит баланс, предоставляя мощные ООП-возможности, но не заставляя их использовать там, где они не нужны.
Асинхронное API
Введение в асинхронное программирование
Асинхронное программирование стало неотъемлемой частью современной Python-разработки и продолжает набирать популярность среди веб-разработчиков.
Основные темы
Итераторы, генераторы и корутины
Итераторы
Итераторы - фундаментальная концепция Python, которую разработчики используют ежедневно, часто не задумываясь об их работе. Любая коллекция в Python (списки, словари, множества, строки, файлы) является итерабельной.
Реализация аналога функции range():
class Range:
def __init__(self, stop_value: int):
self.current = -1
self.stop_value = stop_value - 1
def __iter__(self):
return RangeIterator(self)
class RangeIterator:
def __init__(self, container):
self.container = container
def __next__(self):
if self.container.current < self.container.stop_value:
self.container.current += 1
return self.container.current
raise StopIteration
Упрощенная версия:
class Range2:
def __init__(self, stop_value: int):
self.current = -1
self.stop_value = stop_value - 1
def __iter__(self):
return self
def __next__(self):
if self.current < self.stop_value:
self.current += 1
return self.current
raise StopIteration
Как работает цикл for под капотом:
iterable = Range2(5)
iterator = iter(iterable)
while True:
try:
value = next(iterator)
print(value)
except StopIteration:
break
Генераторы
Генераторы работают на принципе запоминания контекста выполнения функции с помощью ключевого слова yield.
Простой пример генератора:
def simple_generator():
yield 1
yield 2
return 3
gen = simple_generator()
print(next(gen)) # 1
print(next(gen)) # 2
print(next(gen)) # StopIteration: 3
Генераторные выражения:
gen_exp = (x for x in range(100000))
print(gen_exp) # <generator object <genexpr> at 0x...>
Синтаксический сахар yield from:
numbers = [1, 2, 3]
# Стандартный подход
def func():
for item in numbers:
yield item
# Упрощенный подход
def func():
yield from numbers
Корутины
Корутины - основные строительные блоки асинхронного программирования, появившиеся как решение проблемы GIL (Global Interpreter Lock).
Пример корутины для финансовых расчетов:
import math
def cash_return_coro(percent: float, years: int) -> float:
value = math.pow(1 + percent / 100, years)
while True:
try:
deposit = (yield)
yield round(deposit * value, 2)
except GeneratorExit:
print('Выход из корутины')
raise
# Использование
coro = cash_return_coro(5, 5)
next(coro)
values = [1000, 2000, 5000, 10000, 100000]
for item in values:
print(coro.send(item))
next(coro)
coro.close()
Асинхронность в Python и asyncio
Типы задач
- CPU bound-задачи - интенсивное использование процессора (математические модели, нейросети, рендеринг)
- I/O bound-задачи - основная работа с вводом/выводом (файловая система, сеть)
- Memory bound-задачи - интенсивная работа с оперативной памятью
Проблема блокирующих операций
import requests
def do_some_logic(data):
pass
def save_to_database(data):
pass
# Блокирующий код
data = requests.get('https://data.aggregator.com/films')
processed_data = do_some_logic(data)
save_to_database(data)
Event Loop - сердце асинхронных программ
Базовая реализация планировщика:
import logging
from typing import Generator
from queue import Queue
class Scheduler:
def __init__(self):
self.ready = Queue()
self.task_map = {}
def add_task(self, coroutine: Generator) -> int:
new_task = Task(coroutine)
self.task_map[new_task.tid] = new_task
self.schedule(new_task)
return new_task.tid
def exit(self, task: Task):
del self.task_map[task.tid]
def schedule(self, task: Task):
self.ready.put(task)
def _run_once(self):
task = self.ready.get()
try:
result = task.run()
except StopIteration:
self.exit(task)
return
self.schedule(task)
def event_loop(self):
while self.task_map:
self._run_once()
Реализация задачи (Task):
import types
from typing import Generator, Union
class Task:
task_id = 0
def __init__(self, target: Generator):
Task.task_id += 1
self.tid = Task.task_id
self.target = target
self.sendval = None
self.stack = []
def run(self):
while True:
try:
result = self.target.send(self.sendval)
if isinstance(result, types.GeneratorType):
self.stack.append(self.target)
self.sendval = None
self.target = result
else:
if not self.stack:
return
self.sendval = result
self.target = self.stack.pop()
except StopIteration:
if not self.stack:
raise
self.sendval = None
self.target = self.stack.pop()
Asyncio
С версии Python 3.5 появился синтаксис async/await для нативных корутин.
Простая программа с asyncio:
import random
import asyncio
async def func():
r = random.random()
await asyncio.sleep(r)
return r
async def value():
result = await func()
print(result)
if __name__ == '__main__':
loop = asyncio.get_event_loop()
loop.run_until_complete(value())
loop.close()
Основные функции asyncio:
gather- одновременное выполнение корутинsleep- приостановка выполненияwait/wait_for- ожидание выполнения корутин
Основные функции event_loop:
get_event_loop- получение объекта цикла событийrun_until_complete/run- запуск асинхронных функцийshutdown_asyncgens- корректное завершениеcall_soon- планирование выполнения
Асинхронные фреймворки
Twisted
Один из старейших асинхронных фреймворков с собственной реализацией event-loop.
Основные концепции:
- Protocol - описание получения и отправки данных
- Factory - управление созданием объектов протокола
- Reactor - собственная реализация event-loop
- Deferred-объекты - цепочки обратных вызовов
Пример Deferred-объекта:
from twisted.internet import defer
def toint(data):
return int(data)
def increment_number(data):
return data + 1
def print_result(data):
print(data)
def handleFailure(f):
print("OOPS!")
def get_deferred():
d = defer.Deferred()
return d.addCallbacks(toint, handleFailure)\
.addCallbacks(increment_number, handleFailure)\
.addCallback(print_result)
Aiohttp
Асинхронные HTTP-клиент и сервер, построенные поверх asyncio.
Пример приложения:
import aiohttp
from aiohttp import web
async def get_phrase():
async with aiohttp.ClientSession() as session:
async with session.get('https://fish-text.ru/get',
params={'type': 'title'}) as response:
result = await response.json(content_type='text/html; charset=utf-8')
return result.get('text')
async def index_handler(request):
return web.Response(text=await get_phrase())
async def response_signal(request, response):
response.text = response.text.upper()
return response
async def make_app():
app = web.Application()
app.on_response_prepare.append(response_signal)
app.add_routes([web.get('/', index_handler)])
return app
web.run_app(make_app())
FastAPI
Современный фреймворк для быстрой разработки API, построенный на Starlette и Pydantic.
Простой пример API:
from fastapi import FastAPI
from pydantic import BaseModel, Field
from typing import Optional
app = FastAPI(title="Простые математические операции")
class Add(BaseModel):
first_number: int = Field(title='Первое слагаемое')
second_number: Optional[int] = Field(title='Второе слагаемое')
class Result(BaseModel):
result: int = Field(title='Результат')
@app.post("/add", response_model=Result)
async def create_item(item: Add):
return {
'result': item.first_number + (item.second_number or 1)
}
Заключение
Вы познакомились с основами асинхронного программирования в Python, изучили ключевые концепции итераторов, генераторов и корутин, освоили работу с asyncio и популярными асинхронными фреймворками.
Полезные ссылки
- https://dbader.org/blog/python-iterators
- https://www.techbeamers.com/python-iterator/
- https://realpython.com/introduction-to-python-generators/
- https://www.python.org/dev/peps/pep-0255
- https://ru.wikipedia.org/wiki/Ленивые_вычисления
- https://medium.com/@chandansingh_99754/python-generators-and-coroutines-d54ed9c343ae
- https://www.youtube.com/watch?v=AXkOli6BsBY
- https://realpython.com/python-sockets/#reference
- https://snarky.ca/how-the-heck-does-async-await-work-in-python-3-5/
Жизненный цикл программного обеспечения
Введение
Жизненный цикл программного обеспечения (ПО) — это процесс, который охватывает все этапы разработки, от возникновения идеи до завершения поддержки продукта. Понимание этих этапов помогает создавать качественное, надежное и востребованное программное обеспечение.
Основные стадии жизненного цикла
Жизненный цикл ПО состоит из шести основных стадий:
- Анализ
- Проектирование
- Разработка
- Тестирование
- Релиз
- Поддержка
Анализ и планирование
На этапе анализа происходит сбор и анализ требований к будущему продукту. Результатом этого этапа является документ Software Requirements Specification (SRS).
IEEE 830-1998
Это стандарт, который рекомендует структуру для документирования требований к ПО. Примерная структура SRS:
- Назначение
- Общее описание
- Конкретные требования
- Интерфейсы
- Ограничения
- Атрибуты качества
Ключевые задачи этапа анализа:
- Планирование
- Определение требований
- Установка целей
- Планирование ресурсов
- Утверждение сроков и бюджетов
Проектирование
На этапе проектирования разрабатывается архитектура системы и интерфейсы на основе технического задания.
Design-review
Проводится для оценки целесообразности реализации системы и качества её проектирования. Обсуждаются:
- Что планируется сделать
- Мотивация (цели, заказчики, пользователи)
- Сравнение с аналогами
- Roadmap
Security-review
Проводится всегда, но особенно важен в случаях:
- Создания нового сервиса
- Работы с финансовыми функциями
- Передачи конфиденциальных данных
- Реализации аутентификации/авторизации
MVP (Minimum Viable Product)
Минимально жизнеспособный продукт — версия продукта с минимальными, но достаточными функциями для удовлетворения первых потребителей.
Разработка
Системы контроля версий (VCS)
VCS — программное обеспечение для управления изменениями в документах и коде.
Преимущества VCS:
- Хранение нескольких версий
- Возврат к предыдущим версиям
- Отслеживание авторов изменений
- Совместная работа
История VCS:
- 1960-е: IEBUPDATE
- 1970-е: SCCS
- 1980-е: RCS, CVS
- 1990-е: SVN, Git
CVCS vs DVCS
- CVCS (Centralized): централизованное хранилище, требуется подключение к серверу
- DVCS (Distributed): каждый разработчик имеет полную копию репозитория
Git
Создан Линусом Торвальдсом в 2005 году для разработки ядра Linux.
Изучение Git
Рекомендуется изучить Git с помощью ресурсов:
- Официальная документация
- Интерактивные tutorials
- Практика работы с ветками
Ветвление в Git
- Легковесное
- Мгновенное
- Поощряется частое ветвление и слияние
Методики ветвления:
- Git Flow
- GitHub Flow
- GitLab Flow
Code-review
Pull Request (PR) — запрос на слияние изменений. Позволяет:
- Обеспечить видимость изменений
- Проводить обсуждение до слияния
- Автоматизировать проверки
Монорепозиторий
Хранение кода нескольких проектов в одном репозитории с единой системой сборки, тестирования и развертывания.
Преимущества:
- Упрощение управления зависимостями
- Упрощение межкомандного взаимодействия
- Централизованное управление версиями
Тестирование
После разработки важно убедиться, что приложение соответствует требованиям.
Виды тестирования:
- Статический анализ кода
- Модульное тестирование (Unit testing)
- Интеграционное тестирование
- Функциональное тестирование
- Нагрузочное тестирование
- Тестирование безопасности
Статический анализ кода
Автоматизированная проверка кода на:
- Соответствие стандартам
- Наличие ошибок и уязвимостей
- Метрики качества (покрытие тестами, цикломатическая сложность, дублирование кода)
"Самое важное, что я сделал как программист за последние годы — это начал агрессивно применять статический анализ кода" — Джон Кармак
Модульное тестирование
Проверка корректности отдельных модулей кода. Позволяет быстро выявлять ошибки при изменениях.
Интеграционное тестирование
Проверка взаимодействия между модулями и внешними системами.
Нагрузочное тестирование
Профили нагрузки:
- Performance testing — постепенное увеличение нагрузки
- Load testing — длительная штатная нагрузка
- Stress testing — нагрузки выше граничных значений
- Spike testing — резкие повышения нагрузки
- Warm-up testing — прогрев перед рабочей нагрузкой
Релиз
Стратегии развертывания:
- Blue-green deployment — две идентичные среды, переключение между ними
- Canary deployment — постепенный rollout на небольшую группу пользователей
- Rolling update — постепенная замена экземпляров приложения
- A/B testing — тестирование разных версий на разных группах пользователей
Feature-флаги
Включение/выключение функциональности без изменения кода. Позволяют:
- Скрывать неготовые функции
- Тестировать на подмножествах пользователей
- Быстро откатывать изменения
Feature freeze
Период запрета выкаток для повышения надежности системы (например, во время высоконагруженных периодов).
Релизные окна
Определенные временные промежутки, когда разрешены выкатки в продакшен.
CI/CD
Непрерывная интеграция (Continuous Integration)
- Хранение кода в VCS
- Code review
- Автоматизированные сборки
- Модульное тестирование
- Статический анализ кода
Непрерывная поставка (Continuous Delivery)
- Хранение дистрибутивов
- Автоматизация развертывания на тестовые среды
- Готовность к развертыванию в любой момент
Непрерывное развертывание (Continuous Deployment)
Автоматическая выкатка в продакшен после прохождения всех проверок.
Сопровождение
Ключевые аспекты поддержки:
- Непрерывный мониторинг
- Сбор и анализ логов
- Дежурства и реагирование на инциденты
- Использование feature-флагов
- Chaos engineering
- Регулярные учения
Завершение жизненного цикла (End of Life)
Рано или поздно каждый сервис завершает свой жизненный цикл. Важно планировать заранее, обеспечивая плавный переход пользователей на альтернативные решения.
Заключение
Понимание и правильное применение принципов жизненного цикла ПО позволяет создавать качественные, надежные и востребованные продукты. Каждый этап важен и вносит свой вклад в успех проекта.
Почему Python не очень быстрый
Python - очень гибкий язык. Однако именно эта гибкость не позволяет делать многие оптимизации.
Эффективные оптимизации закладываются на предположения и ограничения.
Меньше ограничений - меньше простора для оптимизации.
1. Динамическая типизация
Чему это мешает:
- Много проверяем в Runtime. Тратим время.
- Не знаем точно с чем работаем - должны все время честно исполнять весь код
2. Изменяемость всего и вся
Несколько примеров:
import builtins
print(len("abc"))
len = lambda obj: "mock!"
print(len("abc"))
len = builtins.len
3
mock!
def my_func(a, b):
return a + b
print(my_func(1, 2))
def new_func(a, b):
return a * b
my_func.__code__ = new_func.__code__
print(my_func(1, 2))
3
2
import sys
import ctypes
def change_local_variable():
# Get prev frame object from the caller
frame = sys._getframe(1)
frame.f_locals['my_var'] = "hello"
# Force update
ctypes.pythonapi.PyFrame_LocalsToFast(ctypes.py_object(frame),
ctypes.c_int(0))
def do_smth():
my_var = 1
change_local_variable()
print(my_var)
do_smth()
hello
Следствие: честно исполняем код
def do1():
a = [-1] * 1000
for i in range(len(a)):
if i == 0:
a[i] = 1
else:
a[i] = i
def do2():
a = [-1] * 1000
a[0] = 1
for i in range(1, len(a)):
a[i] = i
%timeit -n100 do1()
%timeit -n100 do2()
42.2 μs ± 970 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
30.6 μs ± 1.14 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
3. CPython
- Старый проект, написан задолго до многоядерных процессоров и т.д.
- Производительность - не самая главная цель
- Необходимость поддерживать совместимость с C API (особенности внутреннего дизайна)
Но есть и хорошое:
https://docs.python.org/3/whatsnew/3.11.html#summary-release-highlights
https://docs.python.org/3/whatsnew/3.11.html#faster-cpython
Будущее:
- https://github.com/faster-cpython/
- Multithreaded Python without the GIL - https://docs.google.com/document/d/18CXhDb1ygxg-YXNBJNzfzZsDFosB5e6BfnXLlejd9l0/edit#
Когда оптимизировать
Premature optimization is the root of all evil
Так ли это?
Утверждение:
В первую очередь мы пишим работающий код, а потом быстрый. Мы будем заниматься оптимизацией, когда функционал будет готов.
Следствие:
Производительность будет одна и та же все время, пока кто-то не найдет легко исправимые вещи, которые сделаю программу быстрее без неоходимости переделки большого количества кода.
Может повезти, а может не повезти.
Правильный путь:
Если вам нужна быстрая программа - сразу обращайте внимание на производительность.
Ваш прототип должен быть быстрый - может даже быстрее, чем финальная версия.
Лучше начать с производительного решения и поддерживать его, чем надеятся, что получится оптимизировать медленное решение.
Антипаттерн: большой комок грязи
If you think good architecture is expensive, try bad architecture.
http://www.laputan.org/mud/mud.html https://ru.wikipedia.org/wiki/%D0%91%D0%BE%D0%BB%D1%8C%D1%88%D0%BE%D0%B9_%D0%BA%D0%BE%D0%BC%D0%BE%D0%BA_%D0%B3%D1%80%D1%8F%D0%B7%D0%B8
Мантра оптимизаций
- Не делай
- Делай это позже
- Делай это оптимально
Как оптимизировать
 Knuth, D. E. 1974. Structured Programming with go to Statements, ACM Comput. Surv. 6, 4 (Dec. 1974), 261-301.
Knuth, D. E. 1974. Structured Programming with go to Statements, ACM Comput. Surv. 6, 4 (Dec. 1974), 261-301.Нужно найти место, куда прикладывать усилия!
Правило 1. Профилируй код
Возможно вы оптимизируете какую-то функцию в 10 раз.
Однако она исполняется всего в 1% случаев.
В итоге польза от такой оптимизации довольно маленькая.
Не надо гадать какая часть чаще всего используется и дольше всего работает.
Профилирование позволяет понять какая именно часть нужно оптимизировать.
Правило 2. Не забывай про корректность
Ваши оптимизации вполне могут сломать код.
Стоит покрыть дополнительными тестами те части, которые вы хотите поменять.
Профилирование
Основной инструментарий:
- cProfile
- pstats
- SnakeViz
Profile demo
Дополнительно хочется выделить два инструмента:
- py-spy - позволяет снять профиль с работающей программы, без изменений кода
- line_profiler - профилирование по строчкам (показывает количество времени проведенную в каждой строчке)
Измерение времени
Иногда хочется просто замерить время, а не снимать полноценный профиль.
Например, когда мы оптимизируем одну конкретную функцию.
Для этого есть модуль timeit
import timeit
setup = '''
s='abcdefghijklmnopqrstuvwxyz'
def reverse_0(s: str) -> str:
reversed_output = ''
s_length = len(s)
for i in range(s_length-1, 0-1, -1):
reversed_output = reversed_output + s[i]
return reversed_output
def reverse_5(s: str) -> str:
return s[::-1]
'''
timeit.timeit('reverse_0(s)', setup, number=10000)
0.020173080999484228
timeit.timeit('reverse_5(s)', setup, number=10000)
0.001456363000215788
Функция timeit замеряет время с помощью функции time.perf_counter.
На время измерений отключается сборщик мусора.
При этом замеряется общее время нужное для N запусков, а не среднее.
Q: Почему все в строках?
A: Сам код timeit сделан в виде шаблоннонй строки, куда подставляются параметры.
Это позволяет сэкономить время на вызове функции, если бы мы ее передавали в виде объекта.
В timeit можно передавать и функции по честному.
В IPython есть упрощение работы с функцией timeit - специальная команда %timeit.
В отличии от функции эта команда выводит среднее время работы и стандартное отклонение.
def reverse_0(s: str) -> str:
reversed_output = ''
s_length = len(s)
for i in range(s_length-1, 0-1, -1):
reversed_output = reversed_output + s[i]
return reversed_output
%timeit -n100 reverse_0('abcdefghijklmnopqrstuvwxyz')
2.09 μs ± 130 ns per loop (mean ± std. dev. of 7 runs, 100 loops each)
Оптимизация
Часть 1. Что оптимизировать
Оптимизация - это не только изменение кода.
Можно выделить следующие уровни оптимизации:
1. Общая архитектура
То как система работает. Какие данные обрабатываются, как обрабатываются, объем данных, хранение и т.д.
2. Алгоритмы и структуры данных
Выбор того или иного алгоритма/структуры данных при обработке.
3. Реализация (код)
Непосредственная реализация алгоритма/структуры данных
4. Оптимизации во время компиляции
5. Оптимизации во время исполнения
Мы будем обсуждать оптимизации на уровнях 3-5.
Однако оптимизации на уровне 1-2 тоже важны.
Более того у них больший потенциал для ускорения, но в тоже время они наиболее сложные.
В целом оптимизация - это не только про скорость, но еще и:
- Память
- Диск (место, I\O)
- Сеть
- Потребление энергии
- И многое другое
Мы обсудим только скорость работы и память.
Оптимизация - может быть сложной.
- На оптимизацию тратится время. Кроме того не факт что ваши оптимизации что-то то дадут
- Скорее всего система в целом станет сложнее, а код непонятнее
- Не любые оптимизации полезны: можно выиграть скорость, но существенно проиграть память
Часть 2. Пишем хороший Python код
Будем оптимизировать 3 уровень - реализацию (код).
Совет 1. Используй builtins
Посчитаем количество элементов в списке:
one_million_elements = [i for i in range(1000000)]
def calc_total(elements):
total = 0
for item in elements:
total += 1
%timeit calc_total(one_million_elements)
31.6 ms ± 404 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit len(one_million_elements)
43.6 ns ± 1.03 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
Пример выше - игрушечный.
Однако в большинстве случаев вместо того, чтобы писать что-то свое лучше использовать готовую функцию из builtins.
Совет 2. Правильная фильтрация
Попробум получить новый список, отфильтровав только нечетные элементы.
Кроме того воспользуемся предыдущим советом и будем использовать filter из builtins.
def my_filter1(elements):
result = []
for item in elements:
if item % 2:
result.append(item)
return result
def my_filter2(elements):
return list(filter(lambda x: x % 2, elements))
%timeit my_filter1(one_million_elements)
45.6 ms ± 344 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit my_filter2(one_million_elements)
76.8 ms ± 780 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Q: Почему код стал медленнее?
A: Потому что у нас есть накладные расходы на создание генератора, а потом превращения генератора в список.
Давайте напишим код, который лучше отражает наши намеренья и будет сразу создавать нужный список:
def my_filter3(elements):
return [item for item in elements if item % 2]
%timeit my_filter3(one_million_elements)
40.3 ms ± 1.01 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
one_million_elements_str = [str(i) for i in range(1000000)]
def str_filter1(elements):
return [item for item in elements if item.isdigit()]
def str_filter2(elements):
return list(filter(str.isdigit, elements))
%timeit str_filter1(one_million_elements_str)
55.3 ms ± 244 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit str_filter2(one_million_elements_str)
49.8 ms ± 166 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Мораль: Не всегда использование builtins и генераторов делает код быстрее.
Стоит проверять конкретно ваш случай.
Совет 3. Правильная проверка вхождений
Напишим код, проверяющий наличие элемента:
def check_in1(elements, number):
for item in elements:
if item == number:
return True
return False
%timeit check_in1(one_million_elements, 500000)
9.02 ms ± 34.1 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit 500000 in one_million_elements
5.65 ms ± 21.4 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Однако, время поиска зависит от того, где именно находится элемент
%timeit 42 in one_million_elements
492 ns ± 2.24 ns per loop (mean ± std. dev. of 7 runs, 1,000,000 loops each)
В Python есть set - стандартный инструмент для такой задачи
one_million_elements_set = set(one_million_elements)
%timeit 500000 in one_million_elements_set
37.3 ns ± 0.345 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
%timeit 42 in one_million_elements_set
23.5 ns ± 0.223 ns per loop (mean ± std. dev. of 7 runs, 10,000,000 loops each)
Однако, конечно же, мы проиграем время при создании множества:
%timeit set(one_million_elements)
46.7 ms ± 358 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Кроме того, конечно же мы проиграли память.
Совет 4. Сортировка
%timeit sorted(one_million_elements)
16.9 ms ± 819 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit one_million_elements.sort()
8.52 ms ± 700 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Мораль: inplace сортировка заметно быстрее. При возможности пользуйтесь именно ей.
Совет 5. Условия if
Условия в конструкции if можно писать по разному:
count = 100000
def check_false1(flag):
for i in range(count):
if flag == False:
pass
def check_false2(flag):
for i in range(count):
if flag is False:
pass
def check_false3(flag):
for i in range(count):
if not flag:
pass
При этом эти варианты работают разное время:
%timeit check_false1(True)
3.7 ms ± 31.6 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit check_false2(True)
2.6 ms ± 9.39 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit check_false3(True)
2.14 ms ± 13.9 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Попробуем угадать какой способ проверки на пустоту быстрее:
if len(elements) == 0:if elements == []:if not element:
def check_empty1(elements):
for i in range(count):
if len(elements) == 0:
pass
def check_empty2(elements):
for i in range(count):
if elements == []:
pass
def check_empty2_new(elements):
for i in range(count):
if elements == list():
pass
def check_empty3(elements):
for i in range(count):
if not elements:
pass
%timeit check_empty1(one_million_elements)
5.98 ms ± 38.9 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit check_empty2(one_million_elements)
5.54 ms ± 53.1 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit check_empty2_new(one_million_elements)
8.73 ms ± 33.4 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit check_empty3(one_million_elements)
2.97 ms ± 43 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Мораль: пользуйтесь самым быстрым способом. Кроме производительности этот способ более Python-way.
Совет 6. Спрашивать разрешения или обрабатывать последствия
Предпололжим мы хотим написать код, который будет обрабатывать объекты как имеющие некоторый аттрибут, так и нет.
class Foo:
attr1 = 'hello'
foo = Foo()
def check_attr1(obj):
for i in range(count):
if hasattr(obj, 'attr1'):
obj.attr1
def check_attr2(obj):
for i in range(count):
try:
obj.attr1
except AttributeError:
pass
Какой способ быстрее?
%timeit check_attr1(foo)
8.42 ms ± 70.3 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit check_attr2(foo)
4.63 ms ± 29.5 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Разница станет еще большей, если нужно будет проверять несколько аттрибутов.
Где подвох?
Предположим, что у объектов в основном нет нужного аттрибута.
class Bar:
pass
bar = Bar()
%timeit check_attr1(bar)
5.91 ms ± 74.3 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit check_attr2(bar)
59.5 ms ± 897 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Мораль: думайте какая ситуация чаще встречается и исходя из этого выбирайте из двух вариантов.
Этот принцип работает для всех ситуаций, например, при создании запроса по сети.
Совет 7. Особенности определения словаря и списка
В Python можно по разному объявлять словарь и список:
def create_list1():
for i in range(count):
a = []
def create_list2():
for i in range(count):
a = list()
def create_dict1():
for i in range(count):
a = {}
def create_dict2():
for i in range(count):
a = dict()
При этом способы через [] и {} быстрее list() и dict() соответственно:
%timeit create_list1()
4.12 ms ± 127 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit create_list2()
7.16 ms ± 164 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit create_dict1()
4.04 ms ± 93.6 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit create_dict2()
7.82 ms ± 115 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Q: Почему есть разница?
A: Обращение к имени занимает время. Интерпретатору нужно найти на что указывает имя. Можно посмотреть на код через модуль dis и убедиться, что код разный.
import dis
dis.dis("[]")
0 0 RESUME 0
1 2 BUILD_LIST 0
4 RETURN_VALUE
import dis
dis.dis("list()")
0 0 RESUME 0
1 2 PUSH_NULL
4 LOAD_NAME 0 (list)
6 CALL 0
14 RETURN_VALUE
Совет 8. Вызов функции
Если есть возможность не вызывать функцию - лучше это сделать.
Вызов функции и создание frame требует значительного количества времени.
def square(num):
return num ** 2
%timeit [square(num) for num in range(10000)]
1.05 ms ± 6.03 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
%timeit [num ** 2 for num in range(10000)]
694 μs ± 6.45 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
Совет 9. Избегайте активной работы с глобальными переменными
count = 100000
some_global = 0
def work_with_global():
global some_global
for i in range(count):
some_global += 1
def work_with_local():
some_local = 0
for i in range(count):
some_local += 1
%timeit work_with_global()
6.98 ms ± 56.6 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
%timeit work_with_local()
4.16 ms ± 41.8 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
some_global = 0
def work_with_global_optimized():
global some_global
some_local = some_global
for i in range(count):
some_local += 1
some_global = some_local
%timeit work_with_global_optimized()
4.14 ms ± 75.4 μs per loop (mean ± std. dev. of 7 runs, 100 loops each)
Совет 10. Для математики используйте соответвующие библиотеки
Не надо пытаться писать математические вычисления на Python.
Используйте готовые библиотеки, которые написаны на C\Fortran
def list_slow():
a = range(10000)
return [i ** 2 for i in a]
%timeit list_slow()
658 μs ± 4.81 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
import numpy as np
def list_fast():
a = np.arange(10000)
return a ** 2
%timeit list_fast()
10.4 μs ± 32.3 ns per loop (mean ± std. dev. of 7 runs, 100,000 loops each)
Danger zone warning
Используйте советы ниже только если это действительно даст какой-то сущетсвенный выигрыш
Совет 11. Множественное присваивание
def create_variables1():
for i in range(10000):
a = 0
b = 1
c = 2
d = 3
e = 4
f = 5
g = 6
h = 7
i = 8
j = 9
def create_variables2():
for i in range(10000):
a, b, c, d, e, f, g, h, i, j = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9
%timeit create_variables1()
616 μs ± 5.26 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
%timeit create_variables2()
503 μs ± 8.69 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
Объявление переменных на одной строчки работает действительно быстрее, но не стоит так делать
Совет 12. Поиск функций и аттрибутов
В Python поиск аттрибута сложная операция. Вызывается __getattr__ и __getattribute__.
Можно найти аттрибут один раз и сохранить его, чтобы не искать повторно:
def squares1(elements):
result = []
for item in elements:
result.append(item)
def squares2(elements):
result = []
append = result.append
for item in elements:
append(item)
%timeit squares1(one_million_elements)
24.6 ms ± 255 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
%timeit squares2(one_million_elements)
29 ms ± 367 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Прочее
Проекты, заслуживающего внимания:
- nimpy - Используем функции на языке Nim из Python
- Pythran - Другой подход к компиляции кода
- Pyston - еще один интерпретатор с JIT-компилятором
Оптимизируем память
Замеряем память
Замерять память в Python - довольно сложно.
import sys
print(sys.getsizeof([i for i in range(1000000)]))
print(sys.getsizeof([i for i in range(100000)]))
8448728
800984
Кажется, что все работает как надо. Однако:
class SomeClass:
def __init__(self, i):
self.i = i
self.j = i * 2
sys.getsizeof([SomeClass(i) for i in range(1000000)])
8448728
Почему-то список из SomeClass занимает столько же места как и список целых чисел.
По факту sys.getsizeof хорошо работает только для простых типов и встроенных структур.
Q: Что делать? A: Использовать профилировщик памяти!
%load_ext memory_profiler
%memit
peak memory: 625.96 MiB, increment: 0.00 MiB
Этот подход тоже не идеален. Он замеряет лишь потребление памяти в один конкретный момент времени.
Поэтому он не может все учитывать, а его результаты будут заметно плавать.
%memit [n for n in range(10000000)]
peak memory: 1007.02 MiB, increment: 377.12 MiB
%memit [n for n in range(1000000)]
peak memory: 632.71 MiB, increment: 0.07 MiB
Можно ли получить memory-leakage в Python
Зависит от того, что считать memory-leakage. Как в C++ - только если явно работать со счетчиком ссылок, так как есть Garbage collection.
Немного подробнее: https://rushter.com/blog/python-garbage-collector/
Однако, можно получить долго-живущие "бесполезные" объекты.
Плюс есть особенности старых версий Python (2.7, до 3.4)
def mutable_argument(arr=[]):
arr.append(42)
return a
def unused_variable_in_long_process(arg1, arg2, arg3, unused_variable):
pass
class ClassCaching:
cache = {}
def calc(arg):
result = cache.get(arg)
if result is not None:
return result
result = do_calc(arg)
cache[arg] = result
return result
Array
array позволяет более компактно хранить объекты примитвных типов.
import array
%memit array.array('q', range(10000000))
peak memory: 702.93 MiB, increment: 70.22 MiB
Подробнее про типы: https://docs.python.org/3/library/array.html
np.array
np.array так же хранит объекты определенных типов и занимает меньше места, чем стандартный list.
%memit np.arange(10000000)
peak memory: 632.75 MiB, increment: 0.00 MiB
tuple vs list
sys.getsizeof([i for i in one_million_elements])
8448728
sys.getsizeof(tuple(one_million_elements))
8000040
sys.getsizeof(list(one_million_elements))
8000056
Slots
Использование __slots__ позволяет заметно сократить объем занимаемой памяти:
class SomeClass:
def __init__(self, i):
self.a = i
self.b = 2 * i
self.c = 3 * i
self.d = 4 * i
self.e = 5 * i
%memit [SomeClass(i) for i in range(1000000)]
peak memory: 880.38 MiB, increment: 247.62 MiB
class SomeClassSlots:
__slots__ = ('a', 'b', 'c', 'd', 'e',)
def __init__(self, i):
self.a = i
self.b = 2 * i
self.c = 3 * i
self.d = 4 * i
self.e = 5 * i
%memit [SomeClassSlots(i) for i in range(1000000)]
peak memory: 853.01 MiB, increment: 217.66 MiB
Кроме того у __slots__ есть дополнительный плюс - ускорение времени обращения к аттрибуту
d1 = SomeClass(0)
d2 = SomeClassSlots(0)
def attr_work(obj):
count = 0
for i in range(10000):
count += obj.a + obj.b + obj.c + obj.d + obj.e
%timeit attr_work(d1)
824 μs ± 20.2 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
%timeit attr_work(d2)
845 μs ± 7.76 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
Однако со __slots__ не очень удобно работать при наследовании - необходимо его указывать в каждом классе иерархии.
bitarray
bitarray - пакет для эффективного хранения набора булевских значений.
Подробнее: https://github.com/ilanschnell/bitarray
import bitarray.util as bu
%memit bu.zeros(10000000)
peak memory: 634.12 MiB, increment: 0.00 MiB
%memit [False for i in range(10000000)]
peak memory: 701.93 MiB, increment: 67.81 MiB
Однако нужно понимать, что на обращение к элементу тратится время.
range - вычисление вместо хранения
a = range(1, 100000, 3)
print(a[10])
print(len(a))
31
33333
Такой же подход можно использовать и для более сложных последовательностей.
Можно использовать смешанный подход с кешированием результата вычислений.
Другой полезный инструментарий
- https://github.com/mgedmin/objgraph
- https://github.com/zhuyifei1999/guppy3
NumPy
Библеотека NumPy предоставляет следующие возможности:
- работать с многомерными массивами (включая матрицы)
- производить быстрое вычисление математических функций на многомерных массивах
Ядром пакета NumPy является объект ndarray
Важные отличия между NumPy arrays и Python sequences:
- NumPy array имеет фиксированную длину, которая определяется в момент его создания (в отличие от Python lists, которые могут расти динамически)
- Элементы в NumPy array должны быть одного типа
- Можно выполнять операции непосредственно над NumPy arrays
Сильные стороны NumPy:
- Vectorization
- Broadcasting
Мотивирующий пример

import numpy as np
Способы создания Numpy arrays
- Конвертация из Python structures
- Генерация с помощью встроенных функций
- Чтение с диска
Конвертация из Python structures
np.array([1, 2, 3, 4, 5])
array([1, 2, 3, 4, 5])
При конвертации можно задавать тип данных с помощью аргумента dtype:
np.array([1, 2, 3, 4, 5], dtype=np.float32)
array([1., 2., 3., 4., 5.], dtype=float32)
Аналогичное преобразование:
np.float32([1, 2, 3, 4, 5])
array([1., 2., 3., 4., 5.], dtype=float32)
Генерация Numpy arrays
- arange — аналог range из Python, которому можно передать нецелочисленный шаг
- linspace — способ равномерно разбить отрезок на n-1 интервал
- logspace — способ разбить отрезок по логарифмической шкале
- zeros — создаёт массив заполненный нулями заданной размерности
- ones — создаёт массив заполненный единицами заданной размерности
- empty — создаёт массив неинициализированный никаким значением заданной размерности
np.arange(0, 5, 0.5)
array([0. , 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5])
np.linspace(0, 5, 11)
array([0. , 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5, 5. ])
np.logspace(0, 9, 10, base=2)
array([ 1., 2., 4., 8., 16., 32., 64., 128., 256., 512.])
np.zeros((2, 2))
array([[0., 0.],
[0., 0.]])
np.ones((2, 2))
array([[1., 1.],
[1., 1.]])
np.empty((2, 2))
array([[1., 1.],
[1., 1.]])
np.diag([1,2,3])
array([[1, 0, 0],
[0, 2, 0],
[0, 0, 3]])
Pазмеры массива храниться в поле shape, а количество размерностей - в ndim
array = np.ones((2, 3,))
print('Размерность массива - %s, количество размерностей - %d'%(array.shape, array.ndim))
array
Размерность массива - (2, 3), количество размерностей - 2
array([[1., 1., 1.],
[1., 1., 1.]])
## Чему равень ndim и shape в следующих случаях
print(np.diag([1,2,3]).shape, np.diag([1,2,3]).ndim)
print(np.zeros((5, 5, 5)).shape, np.zeros((5, 5, 5)).ndim)
(3, 3) 2
(5, 5, 5) 3
Метод reshape позволяет преобразовать размеры массива без изменения данных
array = np.arange(0, 6, 0.5)
array = array.reshape((2, 6))
array
array([[0. , 0.5, 1. , 1.5, 2. , 2.5],
[3. , 3.5, 4. , 4.5, 5. , 5.5]])
Для того что бы развернуть многомерный массив в вектор, можно воспользоваться функцией ravel
array = np.ravel(array)
array
array([0. , 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5, 5. , 5.5])
# Какие будут массивы?
print(np.ravel(np.diag([1,2])))
print(np.reshape(np.diag([1,2]), [1, 4]))
[1 0 0 2]
[[1 0 0 2]]
Индексация
В NumPy работает привычная индексация Python, включая использование отрицательных индексов и срезов
print(array[0])
print(array[-1])
print(array[1:-1])
print(array[1:-1:2])
print(array[::-1])
0.0
5.5
[0.5 1. 1.5 2. 2.5 3. 3.5 4. 4.5 5. ]
[0.5 1.5 2.5 3.5 4.5]
[5.5 5. 4.5 4. 3.5 3. 2.5 2. 1.5 1. 0.5 0. ]
print(array.shape)
(12,)
print(array[None,0:, None].ndim, array[None,0:, None].shape)
array[None,0:, None]
3 (1, 12, 1)
array([[[0. ],
[0.5],
[1. ],
[1.5],
[2. ],
[2.5],
[3. ],
[3.5],
[4. ],
[4.5],
[5. ],
[5.5]]])
Замечание: Индексы и срезы в многомерных массивах не нужно разделять квадратными скобками
т.е. вместо matrix[i][j] нужно использовать matrix[i, j]
В качестве индексов можно использовать массивы:
array[[0, 2, 4, 6, 8, 10]]
array([0., 1., 2., 3., 4., 5.])
array[[True, False, True, False, True, False, True, False, True, False, True, False]]
array([0., 1., 2., 3., 4., 5.])
# Что будет выведено?
x = np.array([[1, 2, 3]])
y = np.array([1, 2, 3])
print (x.shape, y.shape)
print(np.array_equal(x, y))
print(np.array_equal(x, y[None, :]))
(1, 3) (3,)
False
True
x = np.arange(10)
x
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
x[(x % 2 == 0) & (x > 5)]
array([6, 8])
print(x)
y = x[x>5]
y *= 2
print(y)
print(x)
[0 1 2 3 4 5 6 7 8 9]
[12 14 16 18]
[0 1 2 3 4 5 6 7 8 9]
Для копирования в numpy есть метод copy
x.copy()
array([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
Чтение данных с помощью функции genfromtxt
with open('out.npz', 'wb') as f:
np.save(f, x)
with open('out.npz', 'rb') as f:
print(f.read())
with open('out.npz', 'rb') as f:
y = np.load(f)
print(y)
b"\x93NUMPY\x01\x00v\x00{'descr': '<i8', 'fortran_order': False, 'shape': (10,), } \n\x00\x00\x00\x00\x00\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00\x02\x00\x00\x00\x00\x00\x00\x00\x03\x00\x00\x00\x00\x00\x00\x00\x04\x00\x00\x00\x00\x00\x00\x00\x05\x00\x00\x00\x00\x00\x00\x00\x06\x00\x00\x00\x00\x00\x00\x00\x07\x00\x00\x00\x00\x00\x00\x00\x08\x00\x00\x00\x00\x00\x00\x00\t\x00\x00\x00\x00\x00\x00\x00"
[0 1 2 3 4 5 6 7 8 9]
iris = np.genfromtxt('iris_subset.txt', delimiter=', ', names=True, dtype=[('sepal_length_in_cm', 'f8'),
('sepal_width_in_cm', 'f8'),
('petal_length_in_cm', 'f8'),
('petal_width_in_cm', 'f8'),
('class', 'U10')])
iris
array([(1.000e+00, 1. , 10., 121. , 'setosa'),
(1.000e+00, 314. , 13., 121. , 'versicolor'),
(1.134e+03, 1. , 103., 1421. , 'setosa'),
(1.000e+00, 141. , 10., 121. , 'versicolor'),
(1.440e+02, 1. , 4582., 13481. , 'versicolor'),
(1.000e+00, 13.3, 10., 121. , 'versicolor'),
(1.141e+03, 1. , 1341., 1231.1, 'setosa'),
(7.320e+02, 131. , 139., 92.1, 'setosa')],
dtype=[('sepal_length_in_cm', '<f8'), ('sepal_width_in_cm', '<f8'), ('petal_length_in_cm', '<f8'), ('petal_width_in_cm', '<f8'), ('class', '<U10')])
Значения строки можно запросить по индексу, а значения колонки по её названию
print('Описание первого элемента: %s'%iris[0])
print('Значения столбца sepal_length_in_cm: %s'%iris['sepal_length_in_cm'])
Описание первого элемента: (1., 1., 10., 121., 'setosa')
Значения столбца sepal_length_in_cm: [1.000e+00 1.000e+00 1.134e+03 1.000e+00 1.440e+02 1.000e+00 1.141e+03
7.320e+02]
sepal_length_setosa = iris['sepal_length_in_cm'][iris['class'] == 'setosa']
sepal_length_versicolor = iris['sepal_length_in_cm'][iris['class'] == 'versicolor']
print('Значения слтобца sepal_length_in_cm\n\tclass setosa: %s\n\tclass versicolor: %s'%(sepal_length_setosa,
sepal_length_versicolor))
Значения слтобца sepal_length_in_cm
class setosa: [1.000e+00 1.134e+03 1.141e+03 7.320e+02]
class versicolor: [ 1. 1. 144. 1.]
При чтение данных из файла можно пропускать строки в конце и в начале, используя skip_header и skip_footer, а также брать только нужные столбцы - usecols
iris_class = np.genfromtxt('iris_subset.txt', delimiter=', ', skip_header=1, usecols=4, dtype='U10')
iris_class
array(['setosa', 'versicolor', 'setosa', 'versicolor', 'versicolor',
'versicolor', 'setosa', 'setosa'], dtype='<U10')
iris_features = np.genfromtxt('iris_subset.txt', delimiter=', ', skip_header=1, usecols=range(4))
iris_features
array([[1.0000e+00, 1.0000e+00, 1.0000e+01, 1.2100e+02],
[1.0000e+00, 3.1400e+02, 1.3000e+01, 1.2100e+02],
[1.1340e+03, 1.0000e+00, 1.0300e+02, 1.4210e+03],
[1.0000e+00, 1.4100e+02, 1.0000e+01, 1.2100e+02],
[1.4400e+02, 1.0000e+00, 4.5820e+03, 1.3481e+04],
[1.0000e+00, 1.3300e+01, 1.0000e+01, 1.2100e+02],
[1.1410e+03, 1.0000e+00, 1.3410e+03, 1.2311e+03],
[7.3200e+02, 1.3100e+02, 1.3900e+02, 9.2100e+01]])
features_setosa = iris_features[iris_class == 'setosa']
features_versicolor = iris_features[iris_class == 'versicolor']
Операции в NumPy можно производить непосредственно над векторами одинаковой размерности без использования циклов
Например, вычисление поэлементной разности между векторами выглядит следующим образом:
sepal_length_versicolor - sepal_length_setosa
array([ 0., -1133., -997., -731.])
Аналогчино для многомерных массивов
features_versicolor - features_setosa
array([[ 0.00000e+00, 3.13000e+02, 3.00000e+00, 0.00000e+00],
[-1.13300e+03, 1.40000e+02, -9.30000e+01, -1.30000e+03],
[-9.97000e+02, 0.00000e+00, 3.24100e+03, 1.22499e+04],
[-7.31000e+02, -1.17700e+02, -1.29000e+02, 2.89000e+01]])
Broadcasting
Broadcasting снимает правило одной размерности и позволяет производить арифметические операции над массивами разных, но всё-таки созгласованных размерностей. Простейшим примером является умножение вектора на число:

2*np.arange(1, 4)
array([2, 4, 6])
Правило согласования размерностей выражается в одном предложение:
In order to broadcast, the size of the trailing axes for both arrays in an operation must either be the same size or one of them must be one
Если количество размерностей не совпадают, то к массиву меньшей размерности добавляются фиктивные размерности "слева", например:
a = np.ones((2,3,4))
b = np.ones(4)
c = a * b # here a.shape=(2,3,4) and b.shape is considered to be (1,1,4)
Прибавим к каждой строчки матрицы один и тот же вектор:

np.array([[0, 0, 0], [10, 10, 10], [20, 20, 20], [30, 30, 30]]) + np.arange(3)
array([[ 0, 1, 2],
[10, 11, 12],
[20, 21, 22],
[30, 31, 32]])
Теперь если мы хотим, проделать тот же трюк но со столбцами, то мы не можем просто добавить вектор состоящий из 4 элементов т.к. в данном случае размеры будут не согласованы

Сначала нужно преоброзовать вектор к виду:
np.arange(4)[:, np.newaxis]
array([[0],
[1],
[2],
[3]])
А затем к нему добавить матрицу:
np.arange(4)[:, np.newaxis]+np.array([[0, 0, 0], [10, 10, 10], [20, 20, 20], [30, 30, 30]])
array([[ 0, 0, 0],
[11, 11, 11],
[22, 22, 22],
[33, 33, 33]])
Так же в NumPy реализованно много полезных операций для работы с массивами: np.min, np.max, np.sum, np.mean и т.д.
print('Среднее значение всех значений класса versicolor: %s'%np.mean(features_versicolor))
print('Среднее значение каждого признака класса versicolor: %s'%np.mean(features_versicolor, axis=1))
Среднее значение всех значений класса versicolor: 1192.20625
Среднее значение каждого признака класса versicolor: [ 112.25 68.25 4552. 36.325]
Теперь эффективно посчитаем $\frac{1}{n} \sum\limits_{i=1}^n |x_i-y_i|$ для каждой пары $(x, y)$, где $x$ - вектор признаков объекта из класса setosa, а $y$ - вектор признаков объекта из класса versicolor
np.mean(np.abs(features_setosa - features_versicolor[:, np.newaxis]), axis=2)
array([[7.900000e+01, 7.090000e+02, 9.727750e+02, 2.672250e+02],
[3.500000e+01, 6.665000e+02, 9.302750e+02, 2.247250e+02],
[4.518750e+03, 4.382250e+03, 4.121975e+03, 4.637475e+03],
[3.075000e+00, 6.345750e+02, 8.983500e+02, 2.516500e+02]])
Операции
x = np.arange(40).reshape(5, 2, 4)
print(x)
[[[ 0 1 2 3]
[ 4 5 6 7]]
[[ 8 9 10 11]
[12 13 14 15]]
[[16 17 18 19]
[20 21 22 23]]
[[24 25 26 27]
[28 29 30 31]]
[[32 33 34 35]
[36 37 38 39]]]
print(x.mean())
print(np.mean(x))
19.5
19.5
x.mean(axis=0)
array([[16., 17., 18., 19.],
[20., 21., 22., 23.]])
x.mean(axis=1)
array([[ 2., 3., 4., 5.],
[10., 11., 12., 13.],
[18., 19., 20., 21.],
[26., 27., 28., 29.],
[34., 35., 36., 37.]])
x.mean(axis=2)
array([[ 1.5, 5.5],
[ 9.5, 13.5],
[17.5, 21.5],
[25.5, 29.5],
[33.5, 37.5]])
x.mean(axis=(0,2))
array([17.5, 21.5])
x.mean(axis=(0,1,2))
19.5
Конкатенация многомерных массивов
Конкатенировать несколько массивом можно с помощью функций np.concatenate, np.hstack, np.vstack, np.dstack
x = np.arange(10).reshape(5, 2)
y = np.arange(100, 120).reshape(5, 4)
x
array([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
y
array([[100, 101, 102, 103],
[104, 105, 106, 107],
[108, 109, 110, 111],
[112, 113, 114, 115],
[116, 117, 118, 119]])
np.hstack((x, y))
array([[ 0, 1, 100, 101, 102, 103],
[ 2, 3, 104, 105, 106, 107],
[ 4, 5, 108, 109, 110, 111],
[ 6, 7, 112, 113, 114, 115],
[ 8, 9, 116, 117, 118, 119]])
x = np.ones([2, 3])
y = np.zeros([2, 2])
# Какой будет результат
print(np.hstack((x,y)).shape)
print(np.vstack((x,y)).shape)
(2, 5)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[54], line 3
1 # Какой будет результат
2 print(np.hstack((x,y)).shape)
----> 3 print(np.vstack((x,y)).shape)
File /opt/anaconda3/lib/python3.12/site-packages/numpy/core/shape_base.py:289, in vstack(tup, dtype, casting)
287 if not isinstance(arrs, list):
288 arrs = [arrs]
--> 289 return _nx.concatenate(arrs, 0, dtype=dtype, casting=casting)
ValueError: all the input array dimensions except for the concatenation axis must match exactly, but along dimension 1, the array at index 0 has size 3 and the array at index 1 has size 2
p = np.arange(1).reshape([1, 1, 1, 1])
p
array([[[[0]]]])
print("vstack: ", np.vstack((p, p)).shape)
print("hstack: ", np.hstack((p, p)).shape)
print("dstack: ", np.dstack((p, p)).shape)
print("concatenate: ", np.concatenate((p, p), axis=3).shape)
vstack: (2, 1, 1, 1)
hstack: (1, 2, 1, 1)
dstack: (1, 1, 2, 1)
concatenate: (1, 1, 1, 2)
Типы
x = [1, 2, 70000]
np.array(x, dtype=np.float32)
array([1.e+00, 2.e+00, 7.e+04], dtype=float32)
np.array(x, dtype=np.uint16)
/tmp/ipykernel_984447/2771282312.py:1: DeprecationWarning: NumPy will stop allowing conversion of out-of-bound Python integers to integer arrays. The conversion of 70000 to uint16 will fail in the future.
For the old behavior, usually:
np.array(value).astype(dtype)
will give the desired result (the cast overflows).
np.array(x, dtype=np.uint16)
array([ 1, 2, 4464], dtype=uint16)
np.array(x, dtype=np.unicode_)
array(['1', '2', '70000'], dtype='<U5')
Функциональное программирование
def f(value):
return np.sqrt(value)
print(np.apply_along_axis(f, 0, np.arange(10)))
[0. 1. 1.41421356 1.73205081 2. 2.23606798
2.44948974 2.64575131 2.82842712 3. ]
vf = np.vectorize(f)
%%timeit
vf(np.arange(100000))
146 ms ± 2.4 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
%%timeit
np.apply_along_axis(f, 0, np.arange(100000))
1.89 ms ± 31.9 μs per loop (mean ± std. dev. of 7 runs, 1,000 loops each)
%%timeit
np.array([f(v) for v in np.arange(100000)])
129 ms ± 861 μs per loop (mean ± std. dev. of 7 runs, 10 loops each)
Pandas
Подключаем библиотеку Pandas, предназначенную для считывания, предобработки и быстрой визуализации данных, а также для простой аналитики.
import pandas as pd
df = pd.read_csv("titanic.csv", sep='\t')
df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 0 | 3 | Braund, Mr. Owen Harris | male | 22.0 | 1 | 0 | A/5 21171 | 7.2500 | NaN | S |
| 1 | 2 | 1 | 1 | Cumings, Mrs. John Bradley (Florence Briggs Th... | female | 38.0 | 1 | 0 | PC 17599 | 71.2833 | C85 | C |
| 2 | 3 | 1 | 3 | Heikkinen, Miss. Laina | female | 26.0 | 0 | 0 | STON/O2. 3101282 | 7.9250 | NaN | S |
view = df[df['Sex'] == 'female']
list(((df['Sex'] == 'female') & (df['Age'] > 30)).index)
[0,
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32,
33,
34,
35,
36,
37,
38,
39,
40,
41,
42,
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55,
56,
57,
58,
59,
60,
61,
62,
63,
64,
65,
66,
67,
68,
69,
70,
71,
72,
73,
74,
75,
76,
77,
78,
79,
80,
81,
82,
83,
84,
85,
86,
87,
88,
89,
90,
91,
92,
93,
94,
95,
96,
97,
98,
99,
100,
101,
102,
103,
104,
105,
106,
107,
108,
109,
110,
111,
112,
113,
114,
115,
116,
117,
118,
119,
120,
121,
122,
123,
124,
125,
126,
127,
128,
129,
130,
131,
132,
133,
134,
135,
136,
137,
138,
139,
140,
141,
142,
143,
144,
145,
146,
147,
148,
149,
150,
151,
152,
153,
154,
155]
df[(df['Sex'] == 'female') & (df['Age'] > 30)].index
Index([1, 3, 11, 15, 18, 25, 40, 52, 61, 85, 98, 123, 132], dtype='int64')
df.drop(index=(df[(df['Sex'] == 'female') & (df['Age'] > 30)].index),axis=1, inplace=True)
df.loc[78]
PassengerId 79
Survived 1
Pclass 2
Name Caldwell, Master. Alden Gates
Sex male
Age 0.83
SibSp 0
Parch 2
Ticket 248738
Fare 29.0
Cabin NaN
Embarked S
Name: 78, dtype: object
df.iloc[0]
PassengerId 1
Survived 0
Pclass 3
Name Braund, Mr. Owen Harris
Sex male
Age 22.0
SibSp 1
Parch 0
Ticket A/5 21171
Fare 7.25
Cabin NaN
Embarked S
Name: 0, dtype: object
df.describe()
| PassengerId | Survived | Pclass | Age | SibSp | Parch | Fare | |
|---|---|---|---|---|---|---|---|
| count | 143.000000 | 143.000000 | 143.000000 | 113.000000 | 143.000000 | 143.000000 | 143.000000 |
| mean | 80.902098 | 0.307692 | 2.461538 | 26.702035 | 0.601399 | 0.391608 | 27.526018 |
| std | 44.536473 | 0.463161 | 0.776134 | 14.483237 | 1.075593 | 0.813919 | 40.406013 |
| min | 1.000000 | 0.000000 | 1.000000 | 0.830000 | 0.000000 | 0.000000 | 6.750000 |
| 25% | 43.500000 | 0.000000 | 2.000000 | 19.000000 | 0.000000 | 0.000000 | 7.925000 |
| 50% | 81.000000 | 0.000000 | 3.000000 | 24.000000 | 0.000000 | 0.000000 | 13.000000 |
| 75% | 118.500000 | 1.000000 | 3.000000 | 33.000000 | 1.000000 | 0.000000 | 29.597900 |
| max | 156.000000 | 1.000000 | 3.000000 | 71.000000 | 5.000000 | 5.000000 | 263.000000 |
df[["Sex", "Cabin"]].describe()
| Sex | Cabin | |
|---|---|---|
| count | 143 | 25 |
| unique | 2 | 23 |
| top | male | C23 C25 C27 |
| freq | 100 | 2 |
Срезы в DataFrame
Индексация
df.sort_values("Age", inplace=True)
df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 78 | 79 | 1 | 2 | Caldwell, Master. Alden Gates | male | 0.83 | 0 | 2 | 248738 | 29.000 | NaN | S |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.00 | 3 | 1 | 349909 | 21.075 | NaN | S |
| 119 | 120 | 0 | 3 | Andersson, Miss. Ellis Anna Maria | female | 2.00 | 4 | 2 | 347082 | 31.275 | NaN | S |
df.iloc[78]
PassengerId 67
Survived 1
Pclass 2
Name Nye, Mrs. (Elizabeth Ramell)
Sex female
Age 29.0
SibSp 0
Parch 0
Ticket C.A. 29395
Fare 10.5
Cabin F33
Embarked S
Name: 66, dtype: object
df.loc[78]
PassengerId 79
Survived 1
Pclass 2
Name Caldwell, Master. Alden Gates
Sex male
Age 0.83
SibSp 0
Parch 2
Ticket 248738
Fare 29.0
Cabin NaN
Embarked S
Name: 78, dtype: object
df.loc[[78, 79, 100], ["Age", "Cabin"]]
| Age | Cabin | |
|---|---|---|
| 78 | 0.83 | NaN |
| 79 | 30.00 | NaN |
| 100 | 28.00 | NaN |
Если хотите модифицировать данные среза, не меняя основной таблицы, нужно сделать копию.
df_slice_copy = df.loc[[78, 79, 100], ["Age", "Cabin"]].copy()
df_slice_copy[:] = 3
df_slice_copy
| Age | Cabin | |
|---|---|---|
| 78 | 3.0 | 3 |
| 79 | 3.0 | 3 |
| 100 | 3.0 | 3 |
Если хотите менять основную таблицу, то используйте loc
df.head(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 78 | 79 | 1 | 2 | Caldwell, Master. Alden Gates | male | 0.83 | 0 | 2 | 248738 | 29.000 | NaN | S |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.00 | 3 | 1 | 349909 | 21.075 | NaN | S |
| 119 | 120 | 0 | 3 | Andersson, Miss. Ellis Anna Maria | female | 2.00 | 4 | 2 | 347082 | 31.275 | NaN | S |
some_slice = df["Age"].isin([20, 25,30])
df.loc[some_slice, "Fare"] = df.loc[some_slice, "Fare"] * 10
Так лучше не делать:
slice_df = df[some_slice]
slice_df["Fare"] = slice_df["Fare"] * 10
/tmp/ipykernel_984447/1355601167.py:2: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
slice_df["Fare"] = slice_df["Fare"] * 10
Получить значения только нужных столбцов можно передав в [] название столбца (или список названий столбцов).
Замечание: Если передаём название одного столбца, то получаем объект класса pandas.Series, а если список названий столбцов, то получаем pandas.DataFrame, чтобы получить numpy.array обратитесь к полю values.
Series и DataFrame имеют много общих методов
df["Age"].head(5)
78 0.83
7 2.00
119 2.00
16 2.00
43 3.00
Name: Age, dtype: float64
df[["Age"]].head(5)
| Age | |
|---|---|
| 78 | 0.83 |
| 7 | 2.00 |
| 119 | 2.00 |
| 16 | 2.00 |
| 43 | 3.00 |
pd.Series
Одномерные срезы датафреймов имеют тип pd.Series.
Можно получить np.array из pd.Series, но вы не хотите этого делать.
df["Age"].head(5).values
array([0.83, 2. , 2. , 2. , 3. ])
Можно достать и индекс
df["Age"].head(5).index
Index([78, 7, 119, 16, 43], dtype='int64')
Создаются они примерно также, как np.array. Опционально указывается индекс
pd.Series([1, 2, 3], index=["Red", "Green", "Blue"])
Red 1
Green 2
Blue 3
dtype: int64
pd.Series(1, index=["Red", "Green", "Blue"])
Red 1
Green 1
Blue 1
dtype: int64
pd.Series([1, 2, 3], index=["Red", "Green", "Blue"])
Red 1
Green 2
Blue 3
dtype: int64
Series можно перевести в DataFrame
s = pd.Series([1, 2, 3], index=["Red", "Green", "Blue"])
s.to_frame("Values")
| Values | |
|---|---|
| Red | 1 |
| Green | 2 |
| Blue | 3 |
s.loc["Red"]
1
s.iloc[0]
1
Объединение таблиц
df1 = df[["Age", "Parch"]].copy()
df2 = df[["Ticket", "Fare"]].copy()
df1.join(df2).head(5)
| Age | Parch | Ticket | Fare | |
|---|---|---|---|---|
| 78 | 0.83 | 2 | 248738 | 29.0000 |
| 7 | 2.00 | 1 | 349909 | 21.0750 |
| 119 | 2.00 | 2 | 347082 | 31.2750 |
| 16 | 2.00 | 1 | 382652 | 29.1250 |
| 43 | 3.00 | 2 | SC/Paris 2123 | 41.5792 |
df1 = df[["Age", "Parch", "PassengerId"]].copy()
df2 = df[["Ticket", "Fare", "PassengerId"]].copy()
pd.merge(df1, df2, on=["PassengerId"]).head(5)
| Age | Parch | PassengerId | Ticket | Fare | |
|---|---|---|---|---|---|
| 0 | 0.83 | 2 | 79 | 248738 | 29.0000 |
| 1 | 2.00 | 1 | 8 | 349909 | 21.0750 |
| 2 | 2.00 | 2 | 120 | 347082 | 31.2750 |
| 3 | 2.00 | 1 | 17 | 382652 | 29.1250 |
| 4 | 3.00 | 2 | 44 | SC/Paris 2123 | 41.5792 |
pd.merge(df1, df2, on=["PassengerId"], how="inner").head(5)
| Age | Parch | PassengerId | Ticket | Fare | |
|---|---|---|---|---|---|
| 0 | 0.83 | 2 | 79 | 248738 | 29.0000 |
| 1 | 2.00 | 1 | 8 | 349909 | 21.0750 |
| 2 | 2.00 | 2 | 120 | 347082 | 31.2750 |
| 3 | 2.00 | 1 | 17 | 382652 | 29.1250 |
| 4 | 3.00 | 2 | 44 | SC/Paris 2123 | 41.5792 |
Группировка
print("Pclass 1: ", df[df["Pclass"] == 1]["Age"].mean())
print("Pclass 2: ", df[df["Pclass"] == 2]["Age"].mean())
print("Pclass 3: ", df[df["Pclass"] == 3]["Age"].mean())
Pclass 1: 36.86363636363637
Pclass 2: 26.68576923076923
Pclass 3: 23.26923076923077
df.groupby(["Pclass"])[["Age"]].mean()
| Age | |
|---|---|
| Pclass | |
| 1 | 36.863636 |
| 2 | 26.685769 |
| 3 | 23.269231 |
df.groupby(["Survived", "Pclass"])
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x73b08903f7d0>
df.groupby(["Survived", "Pclass"])["PassengerId"].count()
Survived Pclass
0 1 18
2 16
3 65
1 1 7
2 11
3 26
Name: PassengerId, dtype: int64
df.groupby(["Survived", "Pclass"])[["PassengerId", "Cabin"]].count()
| PassengerId | Cabin | ||
|---|---|---|---|
| Survived | Pclass | ||
| 0 | 1 | 18 | 12 |
| 2 | 16 | 1 | |
| 3 | 65 | 1 | |
| 1 | 1 | 7 | 7 |
| 2 | 11 | 2 | |
| 3 | 26 | 2 |
df.groupby(["Survived", "Pclass"])[["PassengerId", "Fare"]].describe()
| PassengerId | Fare | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | mean | std | min | 25% | 50% | 75% | max | count | mean | std | min | 25% | 50% | 75% | max | ||
| Survived | Pclass | ||||||||||||||||
| 0 | 1 | 18.0 | 82.555556 | 44.501450 | 7.0 | 40.75 | 88.5 | 117.00 | 156.0 | 18.0 | 80.035183 | 66.109719 | 27.7208 | 51.896875 | 61.2771 | 78.721875 | 263.0000 |
| 2 | 16.0 | 107.187500 | 44.842270 | 21.0 | 72.50 | 122.0 | 145.25 | 151.0 | 16.0 | 33.555725 | 32.412477 | 10.5000 | 12.881250 | 23.5000 | 31.740600 | 130.0000 | |
| 3 | 65.0 | 80.892308 | 42.930585 | 1.0 | 49.00 | 87.0 | 114.00 | 155.0 | 65.0 | 19.123272 | 20.710190 | 6.7500 | 7.895800 | 8.0500 | 21.075000 | 98.2500 | |
| 1 | 1 | 7.0 | 84.000000 | 49.568135 | 24.0 | 44.00 | 89.0 | 117.50 | 152.0 | 7.0 | 90.966057 | 85.998766 | 26.2833 | 35.500000 | 63.3583 | 106.560400 | 263.0000 |
| 2 | 11.0 | 57.181818 | 35.261362 | 10.0 | 33.00 | 57.0 | 73.00 | 134.0 | 11.0 | 21.627273 | 10.581905 | 10.5000 | 11.750000 | 26.0000 | 28.375000 | 41.5792 | |
| 3 | 26.0 | 72.807692 | 46.318048 | 3.0 | 34.00 | 72.0 | 109.50 | 147.0 | 26.0 | 16.698400 | 24.254889 | 7.1417 | 7.756250 | 7.9250 | 14.244775 | 124.7500 | |
Работа с timestamp'ами
tdf = df.copy()
tdf["ts"] = range(1560000000, 1560000000 + tdf.shape[0])
tdf.head(2)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | ts | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 78 | 79 | 1 | 2 | Caldwell, Master. Alden Gates | male | 0.83 | 0 | 2 | 248738 | 29.000 | NaN | S | 1560000000 |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.00 | 3 | 1 | 349909 | 21.075 | NaN | S | 1560000001 |
tdf["ts"] = pd.to_datetime(tdf["ts"], unit="s")
tdf.head(2)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | ts | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 78 | 79 | 1 | 2 | Caldwell, Master. Alden Gates | male | 0.83 | 0 | 2 | 248738 | 29.000 | NaN | S | 2019-06-08 13:20:00 |
| 7 | 8 | 0 | 3 | Palsson, Master. Gosta Leonard | male | 2.00 | 3 | 1 | 349909 | 21.075 | NaN | S | 2019-06-08 13:20:01 |
tdf.set_index("ts", inplace=True)
tdf.resample("15s").sum()[["PassengerId", "Survived", "Pclass", "Sex"]]
| PassengerId | Survived | Pclass | Sex | |
|---|---|---|---|---|
| ts | ||||
| 2019-06-08 13:20:00 | 862 | 7 | 41 | malemalefemalemalefemalemalefemalefemalemalefe... |
| 2019-06-08 13:20:15 | 1302 | 4 | 40 | femalefemalefemalefemalemalemalefemalefemalefe... |
| 2019-06-08 13:20:30 | 1235 | 3 | 38 | malemalefemalefemalemalemalemalemalemalemalema... |
| 2019-06-08 13:20:45 | 1628 | 6 | 33 | femalefemalemalemalemalemalemalemalefemalemale... |
| 2019-06-08 13:21:00 | 1057 | 5 | 37 | malemalemalemalefemalefemalemalefemalemalemale... |
| 2019-06-08 13:21:15 | 1144 | 6 | 37 | malemalefemalefemalemalefemalemalemalemalemale... |
| 2019-06-08 13:21:30 | 1590 | 0 | 28 | malemalemalemalemalemalemalemalemalemalemalema... |
| 2019-06-08 13:21:45 | 845 | 4 | 33 | malemalemalemalemalemalemalemalemalemalefemale... |
| 2019-06-08 13:22:00 | 912 | 6 | 41 | femalemalemalemalemalefemalemalemalemalemalema... |
| 2019-06-08 13:22:15 | 994 | 3 | 24 | malemalefemalemalemalefemalefemalemale |
Rolling функции

tdf.sort_index(inplace=True)
tdf[["Fare"]].rolling(window=5).mean().head(10)
| Fare | |
|---|---|
| ts | |
| 2019-06-08 13:20:00 | NaN |
| 2019-06-08 13:20:01 | NaN |
| 2019-06-08 13:20:02 | NaN |
| 2019-06-08 13:20:03 | NaN |
| 2019-06-08 13:20:04 | 30.41084 |
| 2019-06-08 13:20:05 | 30.19084 |
| 2019-06-08 13:20:06 | 29.31584 |
| 2019-06-08 13:20:07 | 28.61084 |
| 2019-06-08 13:20:08 | 30.72334 |
| 2019-06-08 13:20:09 | 26.62250 |
Можно делать вместе с groupby
rol = tdf[["Sex", "Fare"]].groupby(["Sex"]).rolling(window=5).mean()
rol.head(100)
| Fare | ||
|---|---|---|
| Sex | ts | |
| female | 2019-06-08 13:20:02 | NaN |
| 2019-06-08 13:20:04 | NaN | |
| 2019-06-08 13:20:06 | NaN | |
| 2019-06-08 13:20:07 | NaN | |
| 2019-06-08 13:20:09 | 27.67584 | |
| ... | ... | ... |
| male | 2019-06-08 13:21:26 | 14.02416 |
| 2019-06-08 13:21:27 | 17.12416 | |
| 2019-06-08 13:21:28 | 12.72000 | |
| 2019-06-08 13:21:29 | 16.34084 | |
| 2019-06-08 13:21:30 | 19.81000 |
100 rows × 1 columns
rol.loc['male'].head(10)
| Fare | |
|---|---|
| ts | |
| 2019-06-08 13:20:00 | NaN |
| 2019-06-08 13:20:01 | NaN |
| 2019-06-08 13:20:03 | NaN |
| 2019-06-08 13:20:05 | NaN |
| 2019-06-08 13:20:08 | 29.35750 |
| 2019-06-08 13:20:11 | 32.93750 |
| 2019-06-08 13:20:12 | 30.97084 |
| 2019-06-08 13:20:19 | 26.98918 |
| 2019-06-08 13:20:20 | 28.28418 |
| 2019-06-08 13:20:26 | 22.64668 |
Работа со строками
df["Name"].str.lower()\
.str.replace(",", " ")\
.str.split(".").str[1]\
.head(10)
78 alden gates
7 gosta leonard
119 ellis anna maria
16 eugene
43 simonne marie anne andree
63 harald
10 marguerite rut
58 constance mirium
50 juha niilo
24 torborg danira
Name: Name, dtype: object
Работа с NaN'ами
df["Cabin"].head(15)
78 NaN
7 NaN
119 NaN
16 NaN
43 NaN
63 NaN
10 G6
58 NaN
50 NaN
24 NaN
147 NaN
59 NaN
125 NaN
39 NaN
9 NaN
Name: Cabin, dtype: object
df["Cabin"].dropna().head(15)
10 G6
136 D47
27 C23 C25 C27
102 D26
151 C2
97 D10 D12
88 C23 C25 C27
118 B58 B60
139 B86
75 F G73
23 A6
66 F33
21 D56
148 F2
137 C123
Name: Cabin, dtype: object
df["Cabin"].fillna(3).head(5)
78 3
7 3
119 3
16 3
43 3
Name: Cabin, dtype: object
df["Cabin"].fillna(method="bfill").head(15)
/tmp/ipykernel_984447/671977776.py:1: FutureWarning: Series.fillna with 'method' is deprecated and will raise in a future version. Use obj.ffill() or obj.bfill() instead.
df["Cabin"].fillna(method="bfill").head(15)
78 G6
7 G6
119 G6
16 G6
43 G6
63 G6
10 G6
58 D47
50 D47
24 D47
147 D47
59 D47
125 D47
39 D47
9 D47
Name: Cabin, dtype: object
pd.isna(df["Cabin"]).head(10)
78 True
7 True
119 True
16 True
43 True
63 True
10 False
58 True
50 True
24 True
Name: Cabin, dtype: bool
Функция apply
def dummpy_example(row):
return row['Sex'] * row['Pclass']
df['dummy_example'] = df.apply(dummpy_example, axis=1)
df.tail(3)
| PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked | dummy_example | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 128 | 129 | 1 | 3 | Peter, Miss. Anna | female | NaN | 1 | 1 | 2668 | 22.3583 | F E69 | C | femalefemalefemale |
| 140 | 141 | 0 | 3 | Boulos, Mrs. Joseph (Sultana) | female | NaN | 0 | 2 | 2678 | 15.2458 | NaN | C | femalefemalefemale |
| 154 | 155 | 0 | 3 | Olsen, Mr. Ole Martin | male | NaN | 0 | 0 | Fa 265302 | 7.3125 | NaN | S | malemalemale |
Визуализация
tdf["Fare"].plot()
<Axes: xlabel='ts'>
tdf["Fare"].resample("10s").mean().plot()
<Axes: xlabel='ts'>
tdf["Sex"].hist()
<Axes: >
Визуализация на Python
Часть 1. Matplotlib
В начале как всегда настроим окружение: импортируем все необходимые библиотеки и немного настроим дефолтное отображение картинок.
! ls
07_manual.ipynb test.ipynb
beam_envelope_bend_test_with_elegant.ipynb test.py
CarPrice_Assignment.csv titanic
developers_rend.html titanic.csv
iris_subset.txt Untitled1.ipynb
NumpyAndPandas.ipynb Untitled2.ipynb
old_warp Untitled.ipynb
out.npz video_games_sales.csv
ozon_student week_2_LinReg.ipynb
pairplot.png week_3_LR_trees.ipynb
practice_vis_py3.ipynb week_4_RF_boosting.ipynb
shared years_stats.html
# # для установки библиотек
# ! pip3 install seaborn
# ! pip3 install plotly
# ! pip3 install ggplot
# ! pip3 install matplotlib
# ! pip3 install matplotlib==3.0.0
# отключим предупреждения Anaconda
import warnings
warnings.simplefilter('ignore')
# будем отображать графики прямо в jupyter'e
%pylab inline
#графики в svg выглядят более четкими
%config InlineBackend.figure_format = 'svg'
#увеличим дефолтный размер графиков
from pylab import rcParams
rcParams['figure.figsize'] = 10,5
import pandas as pd
import seaborn as sns
%pylab is deprecated, use %matplotlib inline and import the required libraries.
Populating the interactive namespace from numpy and matplotlib
После этого загрузим в dataframe данные, с которыми будем работать. Для примеров визуализаций я выбрала данные о продажах и оценках видео-игр с Kaggle Datasets. Данные об оценках игр есть не для всех строк, поэтому сразу оставим только те записи, по которым есть полные данные.
df = pd.read_csv('video_games_sales.csv')
print(df.shape)
(16719, 16)
df.head()
| Name | Platform | Year_of_Release | Genre | Publisher | NA_Sales | EU_Sales | JP_Sales | Other_Sales | Global_Sales | Critic_Score | Critic_Count | User_Score | User_Count | Developer | Rating | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Wii Sports | Wii | 2006.0 | Sports | Nintendo | 41.36 | 28.96 | 3.77 | 8.45 | 82.53 | 76.0 | 51.0 | 8 | 322.0 | Nintendo | E |
| 1 | Super Mario Bros. | NES | 1985.0 | Platform | Nintendo | 29.08 | 3.58 | 6.81 | 0.77 | 40.24 | NaN | NaN | NaN | NaN | NaN | NaN |
| 2 | Mario Kart Wii | Wii | 2008.0 | Racing | Nintendo | 15.68 | 12.76 | 3.79 | 3.29 | 35.52 | 82.0 | 73.0 | 8.3 | 709.0 | Nintendo | E |
| 3 | Wii Sports Resort | Wii | 2009.0 | Sports | Nintendo | 15.61 | 10.93 | 3.28 | 2.95 | 32.77 | 80.0 | 73.0 | 8 | 192.0 | Nintendo | E |
| 4 | Pokemon Red/Pokemon Blue | GB | 1996.0 | Role-Playing | Nintendo | 11.27 | 8.89 | 10.22 | 1.00 | 31.37 | NaN | NaN | NaN | NaN | NaN | NaN |
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 16719 entries, 0 to 16718
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Name 16717 non-null object
1 Platform 16719 non-null object
2 Year_of_Release 16450 non-null float64
3 Genre 16717 non-null object
4 Publisher 16665 non-null object
5 NA_Sales 16719 non-null float64
6 EU_Sales 16719 non-null float64
7 JP_Sales 16719 non-null float64
8 Other_Sales 16719 non-null float64
9 Global_Sales 16719 non-null float64
10 Critic_Score 8137 non-null float64
11 Critic_Count 8137 non-null float64
12 User_Score 10015 non-null object
13 User_Count 7590 non-null float64
14 Developer 10096 non-null object
15 Rating 9950 non-null object
dtypes: float64(9), object(7)
memory usage: 2.0+ MB
df = df.dropna()
print(df.shape)
(6825, 16)
df.head()
| Name | Platform | Year_of_Release | Genre | Publisher | NA_Sales | EU_Sales | JP_Sales | Other_Sales | Global_Sales | Critic_Score | Critic_Count | User_Score | User_Count | Developer | Rating | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Wii Sports | Wii | 2006.0 | Sports | Nintendo | 41.36 | 28.96 | 3.77 | 8.45 | 82.53 | 76.0 | 51.0 | 8 | 322.0 | Nintendo | E |
| 2 | Mario Kart Wii | Wii | 2008.0 | Racing | Nintendo | 15.68 | 12.76 | 3.79 | 3.29 | 35.52 | 82.0 | 73.0 | 8.3 | 709.0 | Nintendo | E |
| 3 | Wii Sports Resort | Wii | 2009.0 | Sports | Nintendo | 15.61 | 10.93 | 3.28 | 2.95 | 32.77 | 80.0 | 73.0 | 8 | 192.0 | Nintendo | E |
| 6 | New Super Mario Bros. | DS | 2006.0 | Platform | Nintendo | 11.28 | 9.14 | 6.50 | 2.88 | 29.80 | 89.0 | 65.0 | 8.5 | 431.0 | Nintendo | E |
| 7 | Wii Play | Wii | 2006.0 | Misc | Nintendo | 13.96 | 9.18 | 2.93 | 2.84 | 28.92 | 58.0 | 41.0 | 6.6 | 129.0 | Nintendo | E |
df['User_Score'] = df.User_Score.astype('float64')
df['Year_of_Release'] = df.Year_of_Release.astype('int64')
df['User_Count'] = df.User_Count.astype('int64')
df['Critic_Count'] = df.Critic_Count.astype('int64')
df.shape
(6825, 16)
Всего в таблице 6825 объектов и 16 признаков для них. Посмотрим на несколько первых записей c помощью метода head, чтобы убедиться, что все распарсилось правильно. Для удобства я оставила только те признаки, которые мы будем в дальнейшем использовать.
useful_cols = ['Name', 'Platform', 'Year_of_Release', 'Genre',
'Global_Sales', 'Critic_Score', 'Critic_Count',
'User_Score', 'User_Count', 'Rating'
]
df[useful_cols].head(10)
| Name | Platform | Year_of_Release | Genre | Global_Sales | Critic_Score | Critic_Count | User_Score | User_Count | Rating | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Wii Sports | Wii | 2006 | Sports | 82.53 | 76.0 | 51 | 8.0 | 322 | E |
| 2 | Mario Kart Wii | Wii | 2008 | Racing | 35.52 | 82.0 | 73 | 8.3 | 709 | E |
| 3 | Wii Sports Resort | Wii | 2009 | Sports | 32.77 | 80.0 | 73 | 8.0 | 192 | E |
| 6 | New Super Mario Bros. | DS | 2006 | Platform | 29.80 | 89.0 | 65 | 8.5 | 431 | E |
| 7 | Wii Play | Wii | 2006 | Misc | 28.92 | 58.0 | 41 | 6.6 | 129 | E |
| 8 | New Super Mario Bros. Wii | Wii | 2009 | Platform | 28.32 | 87.0 | 80 | 8.4 | 594 | E |
| 11 | Mario Kart DS | DS | 2005 | Racing | 23.21 | 91.0 | 64 | 8.6 | 464 | E |
| 13 | Wii Fit | Wii | 2007 | Sports | 22.70 | 80.0 | 63 | 7.7 | 146 | E |
| 14 | Kinect Adventures! | X360 | 2010 | Misc | 21.81 | 61.0 | 45 | 6.3 | 106 | E |
| 15 | Wii Fit Plus | Wii | 2009 | Sports | 21.79 | 80.0 | 33 | 7.4 | 52 | E |
Начнем с самого простого и зачастую удобного способа визуализировать данные из pandas dataframe — это воспользоваться функцией plot.
Для примера построим график продаж видео игр в различных странах в зависимости от года. Для начала отфильтруем только нужные нам столбцы, затем посчитаем суммарные продажи по годам и у получившегося dataframe вызовем функцию plot без параметров.
В библиотеку pandas встроен wrapper для matplotlib.
[x for x in df.columns if 'Sales' in x]
['NA_Sales', 'EU_Sales', 'JP_Sales', 'Other_Sales', 'Global_Sales']
df1 = df[[x for x in df.columns if 'Sales' in x] + ['Year_of_Release']]\
.groupby('Year_of_Release').sum()
df1.head()
| NA_Sales | EU_Sales | JP_Sales | Other_Sales | Global_Sales | |
|---|---|---|---|---|---|
| Year_of_Release | |||||
| 1985 | 0.00 | 0.03 | 0.00 | 0.01 | 0.03 |
| 1988 | 0.00 | 0.02 | 0.00 | 0.01 | 0.03 |
| 1992 | 0.02 | 0.00 | 0.00 | 0.00 | 0.03 |
| 1994 | 0.39 | 0.26 | 0.53 | 0.08 | 1.27 |
| 1996 | 7.91 | 6.88 | 4.06 | 1.24 | 20.10 |
df1.plot();

В этом случае мы сконцентрировались на отображении трендов продаж в разных регионах.
C помощью параметра kind можно изменить тип графика, например, на bar chart. Matplotlib позволяет очень гибко настраивать графики. На графике можно изменить почти все, что угодно, но потребуется порыться в документации и найти нужные параметры. Например, параметра rot отвечает за угол наклона подписей к оси x.
df1.plot(kind='bar', rot=45, stacked=True);

Или можем сделать stacked bar chart, чтобы показать и динамику продаж и их разбиение по рынкам.
df1[list(filter(lambda x: x != 'Global_Sales', df1.columns))]\
.plot(kind='bar', rot=45, stacked=True);

df1[list(filter(lambda x: x != 'Global_Sales', df1.columns))]\
.plot(kind='area', rot=45);

Еще один часто встречающийся тип графиков - это гистограммы. Посмотрим на распределение оценок критиков.
df.Critic_Score.hist(bins = 20)
<Axes: >

ax = df.Critic_Score.hist()
ax.set_title('Critic Score distribution')
ax.set_xlabel('critic score')
ax.set_ylabel('games')
Text(0, 0.5, 'games')

У гистограмм можно контролировать, на сколько групп мы разбиваем распределение с помощью параметра bins.
ax = df.Critic_Score.hist(bins = 20)
ax.set_title('Critic Score distribution')
ax.set_xlabel('critic score')
ax.set_ylabel('games')
Text(0, 0.5, 'games')

Еще немного познакомимся с тем, как в pandas можно стилизовать таблицы.
top_developers_df = df.groupby('Developer')[['Global_Sales']].sum()\
.sort_values('Global_Sales', ascending=False).head(10)
top_developers_df
| Global_Sales | |
|---|---|
| Developer | |
| Nintendo | 529.90 |
| EA Sports | 145.93 |
| EA Canada | 131.46 |
| Rockstar North | 119.47 |
| Capcom | 114.52 |
| Treyarch | 101.37 |
| Ubisoft Montreal | 101.24 |
| Ubisoft | 94.53 |
| EA Tiburon | 79.77 |
| Infinity Ward | 77.56 |
# ! pip3 install jinja2
top_developers_df.style.bar()
| Global_Sales | |
|---|---|
| Developer | |
| Nintendo | 529.900000 |
| EA Sports | 145.930000 |
| EA Canada | 131.460000 |
| Rockstar North | 119.470000 |
| Capcom | 114.520000 |
| Treyarch | 101.370000 |
| Ubisoft Montreal | 101.240000 |
| Ubisoft | 94.530000 |
| EA Tiburon | 79.770000 |
| Infinity Ward | 77.560000 |
with open('developers_rend.html', 'w') as f:
f.write(top_developers_df.style.bar().render())
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[94], line 2
1 with open('developers_rend.html', 'w') as f:
----> 2 f.write(top_developers_df.style.bar().render())
AttributeError: 'Styler' object has no attribute 'render'
Полезные ссылки
Часть 2. Seaborn
Теперь давайте перейдем к библиотеке seaborn. Seaborn — это по сути более высокоуровневое API на базе библиотеки matplotlib. Seaborn содержит более адекватные дефолтные настройки оформления графиков. Если просто добавить в код import seaborn, то картинки станут гораздо симпатичнее. Также в библиотеке есть достаточно сложные типы визуализации, которые в matplotlib потребовали бы большого количество кода.
Познакомимся с первым таким "сложным" типом графиков pair plot (scatter plot matrix). Эта визуализация поможет нам посмотреть на одной картинке, как связаны между собой различные признаки.
import seaborn as sns
# c svg pairplot браузер начинает тормозить
%config InlineBackend.figure_format = 'png'
sns_plot = sns.pairplot(
df[['Global_Sales', 'Critic_Score', 'User_Score']]);
sns_plot.savefig('pairplot.png')
Также с помощью seaborn можно построить распределение, для примера посмотрим на распределение оценок критиков Critic_Score. Для этого построим distplot. По default'у на графике отображается гистограмма и kernel density estimation.
%config InlineBackend.figure_format = 'svg'
sns.distplot(df.Critic_Score);

Для того чтобы подробнее посмотреть на взаимосвязь двух численных признаков, есть еще и joint_plot – это гибрид scatter plot и histogram (отображаются также гистограммы распределений признаков). Посмотрим на то, как связаны между собой оценка критиков Critic_Score и оценка пользователя User_Score.
sns.jointplot(x='Critic_Score', y='User_Score',
data=df, kind='scatter');

sns.jointplot(x='Critic_Score', y='User_Score',
data=df, kind='reg');

Еще один полезный тип графиков - это box plot. Давайте сравним пользовательские оценки игр для топ-5 крупнейших игровых платформ.
top_platforms = df.Platform.value_counts().sort_values(ascending = False).head(5).index.values
sns.boxplot(x="Platform", y="Critic_Score",
data=df[df.Platform.isin(top_platforms)])
<Axes: xlabel='Platform', ylabel='Critic_Score'>

Думаю, стоит обсудить немного подробнее, как же понимать box plot. Box plot состоит из коробки (поэтому он и называется box plot), усиков и точек. Коробка показывает интерквантильный размах распределения, то есть соответственно 25% (Q1) и 75% (Q3) процентили. Черта внутри коробки обозначает медиану распределения.
С коробкой разобрались, перейдем к усам. Усы отображают весь разброс точек кроме выбросов, то есть минимальные и максимальные значения, которые попадают в промежуток (Q1 - 1.5*IQR, Q3 + 1.5*IQR), где IQR = Q3 - Q1 - интерквантильный размах. Точками на графике обозначаются выбросы (outliers) - те значения, которые не вписываются в промежуток значений, заданный усами графика.
И еще один тип графиков (последний из тех, которые мы рассмотрим в этой части) - это heat map. Heat map позволяет посмотреть на распределение какого-то численного признака по двум категориальным. Визуализируем суммарные продажи игр по жанрам и игровым платформам.
platform_genre_sales = df.pivot_table(
index='Platform',
columns='Genre',
values='Global_Sales',
aggfunc=sum).fillna(0).applymap(float)
platform_genre_sales
| Genre | Action | Adventure | Fighting | Misc | Platform | Puzzle | Racing | Role-Playing | Shooter | Simulation | Sports | Strategy |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Platform | ||||||||||||
| 3DS | 30.81 | 2.00 | 2.63 | 4.48 | 27.61 | 2.63 | 13.89 | 18.94 | 1.02 | 16.08 | 2.20 | 0.94 |
| DC | 0.00 | 1.33 | 0.56 | 0.00 | 0.12 | 0.00 | 0.20 | 0.68 | 0.05 | 0.52 | 1.09 | 0.00 |
| DS | 42.43 | 8.83 | 3.37 | 68.82 | 55.02 | 50.50 | 29.93 | 60.31 | 6.40 | 42.71 | 6.01 | 8.00 |
| GBA | 23.21 | 4.54 | 3.28 | 8.59 | 40.36 | 5.47 | 12.60 | 21.00 | 1.40 | 2.03 | 5.93 | 3.34 |
| GC | 29.99 | 4.56 | 15.81 | 12.72 | 24.67 | 3.31 | 11.09 | 12.48 | 13.04 | 8.39 | 19.91 | 3.45 |
| PC | 25.45 | 1.42 | 0.13 | 3.02 | 0.46 | 0.19 | 3.18 | 44.68 | 36.34 | 40.34 | 6.54 | 25.37 |
| PS | 54.93 | 1.10 | 18.91 | 5.66 | 18.92 | 0.26 | 34.17 | 44.07 | 5.86 | 1.67 | 20.75 | 0.25 |
| PS2 | 238.73 | 10.74 | 64.72 | 38.70 | 52.34 | 3.97 | 127.17 | 77.30 | 98.20 | 34.01 | 191.88 | 8.21 |
| PS3 | 262.38 | 16.18 | 47.83 | 26.59 | 20.91 | 0.40 | 62.17 | 64.00 | 174.54 | 7.91 | 98.20 | 3.19 |
| PS4 | 76.92 | 3.09 | 6.86 | 2.70 | 6.16 | 0.03 | 9.08 | 18.18 | 63.67 | 0.72 | 55.16 | 0.46 |
| PSP | 43.92 | 2.81 | 12.36 | 5.09 | 10.84 | 2.04 | 27.88 | 31.11 | 18.52 | 4.61 | 25.34 | 3.40 |
| PSV | 9.53 | 1.28 | 1.91 | 1.81 | 2.49 | 0.12 | 1.00 | 7.02 | 3.88 | 0.00 | 1.84 | 0.00 |
| Wii | 75.75 | 7.72 | 21.89 | 149.42 | 78.25 | 8.22 | 48.35 | 11.01 | 19.20 | 23.88 | 213.53 | 1.76 |
| WiiU | 13.61 | 0.08 | 1.22 | 10.93 | 21.33 | 1.30 | 7.09 | 1.26 | 5.56 | 0.20 | 2.39 | 1.11 |
| X360 | 209.90 | 11.52 | 35.30 | 70.09 | 10.26 | 0.36 | 56.14 | 68.62 | 260.35 | 13.02 | 109.74 | 8.00 |
| XB | 36.53 | 1.98 | 10.92 | 3.56 | 7.44 | 0.10 | 23.44 | 12.50 | 60.33 | 6.60 | 46.75 | 1.92 |
| XOne | 29.07 | 1.57 | 2.25 | 4.08 | 0.62 | 0.00 | 8.84 | 8.21 | 48.12 | 0.01 | 26.59 | 0.21 |
sns.heatmap(platform_genre_sales, annot=False, fmt=".1f", center = True);

Полезные ссылки
Часть 3. Plotly
Мы рассмотрели визуализации на базе библиотеки matplotlib. Однако, это не единственная опция для построения графиков на языке python. Познакомимся также с библиотекой plotly. Plotly - это open-source библиотека, которая позволяет строить интерактивные графики в jupyter.notebook'e без необходимости зарываться в javascript код.
Прелесть интерактивных графиков заключается в том, что можно посмотреть точное численное значение при наведении мыши, скрыть неинтересные ряды в визуализации, приблизить определенный участок графика и т.д.
Перед началом работы импортируем все необходимые модули и инициализируем plotly с помощью команды init_notebook_mode.
from plotly.offline import init_notebook_mode, iplot
import plotly.graph_objects as go
import plotly
import plotly.graph_objs as go
init_notebook_mode(connected=True)
Для начала построим line plot с динамикой числа вышедших игр и их продаж по годам.
global_sales_years_df = df.groupby('Year_of_Release')[['Global_Sales']].sum()
global_sales_years_df.head()
| Global_Sales | |
|---|---|
| Year_of_Release | |
| 1985 | 0.03 |
| 1988 | 0.03 |
| 1992 | 0.03 |
| 1994 | 1.27 |
| 1996 | 20.10 |
released_years_df = df.groupby('Year_of_Release')[['Name']].count()
released_years_df.head()
| Name | |
|---|---|
| Year_of_Release | |
| 1985 | 1 |
| 1988 | 1 |
| 1992 | 1 |
| 1994 | 1 |
| 1996 | 7 |
years_df = global_sales_years_df.join(released_years_df)
years_df.head()
| Global_Sales | Name | |
|---|---|---|
| Year_of_Release | ||
| 1985 | 0.03 | 1 |
| 1988 | 0.03 | 1 |
| 1992 | 0.03 | 1 |
| 1994 | 1.27 | 1 |
| 1996 | 20.10 | 7 |
years_df.columns = ['Global_Sales', 'Number_of_Games']
years_df.head()
| Global_Sales | Number_of_Games | |
|---|---|---|
| Year_of_Release | ||
| 1985 | 0.03 | 1 |
| 1988 | 0.03 | 1 |
| 1992 | 0.03 | 1 |
| 1994 | 1.27 | 1 |
| 1996 | 20.10 | 7 |
В plotly строится визуализация объекта Figure, который состоит из данных (массив линий, которые в библиотеке называются traces) и оформления/стиля, за который отвечает объект layout. В простых случаях можно вызывать функцию iplot и просто от массива traces.
trace0 = go.Scatter(
x=years_df.index,
y=years_df.Global_Sales,
name='Global Sales'
)
trace1 = go.Scatter(
x=years_df.index,
y=years_df.Number_of_Games,
name='Number of games released'
)
data = [trace0, trace1]
layout = {'title': 'Statistics of video games'}
fig = go.Figure(data=data, layout=layout)
#fig.show()
iplot(fig, show_link = False)